Introduction à Apache Hadoop : Généralités sur HDFS et MapReduce (partie 1)
- Généralités
- Intérêt et usages
- Hadoop Distributed File System (HDFS)
- MapReduce
- Écosystème Hadoop : une foire aux sous-projets
- Jeux de données
- Conclusion et perspectives
- Références
Ce premier article introductif s’intéresse à présenter le système de fichiers HDFS (Hadoop Distributed File System) et le modèle de programmation MapReduce.
Mes articles consacrés à Hadoop sont décrits ci-dessous :
- Généralités sur HDFS et MapReduce ;
- Installation et configuration d’un cluster simple nœud avec Cloudera CDH 5 ;
- Installation, supervision et performance d’un cluster multi-nœud avec Cloudera CDH 5 ;
- Développement, test et débogage de programmes MapReduce avec Cloudera CDH 5.
Je tiens à préciser que je ne suis pas un spécialiste d’Hadoop. Ces articles sont le résultat d’une veille technologique. Ils seront sûrement améliorés au fur et à mesure de mes différentes découvertes et de l’exploitation d’Hadoop lors de cas réels.
L’objectif visé par ces articles est de démystifier Apache Hadoop et de tenter de rendre sa compréhension aussi facile qu’un jeu d’enfant.
Généralités
Nous sommes actuellement dans l’ère de la production massive de données (BigData) dont une définition implique trois dimensions (3Vs) : Volume, Variété et Vélocité (fréquence). Les sources de données sont nombreuses. D’une part les applications génèrent des données issues des logs, des réseaux de capteurs, des rapports de transactions, des traces de GPS, etc. et d’autre part, les individus produisent des données telles que des photographies, des vidéos, des musiques ou encore des données sur l’état de santé (rythme cardiaque, pression ou poids).
Un problème se pose alors quant au stockage et à l’analyse des données. La capacité de stockage des disques durs augmente mais le temps de lecture croît également. Il devient alors nécessaire de paralléliser les traitements en stockant sur plusieurs unités de disques durs. Toutefois, cela soulève forcément le problème de fiabilité des disques durs qui engendre la panne matérielle. La solution envisagée est la duplication des données comme le ferait un système RAID.
Apache Hadoop (High-availability distributed object-oriented platform) est un système distribué qui répond à ces problématiques. D’une part, il propose un système de stockage distribué via son système de fichier HDFS (Hadoop Distributed File System) et ce dernier offre la possibilité de stocker la donnée en la dupliquant, un cluster Hadoop n’a donc pas besoin d’être configuré avec un système RAID qui devient inutile. D’autre part, Hadoop fournit un système d’analyse des données appelé MapReduce. Ce dernier officie sur le système de fichiers HDFS pour réaliser des traitements sur des gros volumes de données.
Hadoop a été créé par Doug Cutting pour les besoins du projet Apache Nutch, un moteur de recherche open source. À noter que Doug Cutting n’est pas un novice puisqu’il a également créé Apache Lucene la bibliothèque de recherche plein texte. Lorsque le projet Apache Nutch a démarré en 2002, les contributeurs ont compris que l’architecture d’origine ne pourrait pas tenir la montée en charge sur plus de 20 milliards de pages depuis le Web. Google publie en 2003 un article présentant l’architecture de son système de fichiers distribué GFS (Google’s distributed filesystem). Google publie ensuite en 2004 un article introduisant le système MapReduce pour l’analyse des données d’un système GFS. Doug Cutting a décidé de reprendre les concepts présentés par les deux articles pour résoudre les problèmes rencontrés depuis le projet Apache Nutch. En 2006, Hadoop devient un sous-projet d’ Apache Lucene et en 2008 un projet indépendant de la fondation Apache.
![]()
Intérêt et usages
Hadoop n’a d’intérêt que s’il est utilisé dans un environnement composé de plusieurs machines. Utiliser Hadoop dans un environnement monomachine, comme nous allons le faire dans le prochain tutoriel, n’a de sens que pour tester la configuration de l’installation ou fournir un environnement de développement MapReduce (prochain article). Hadoop n’a également pas d’intérêt pour les données de petite taille. C’est même l’effet inverse qui pourrait se produire. Si les données ne dépassent pas les limites de la mémoire ou des disques durs du marché (actuellement la limite est aux alentours de cinq téraoctets), posez-vous la question sur l’utilité d’utiliser Hadoop face à des solutions utilisant des bases de données relationnelles. Vous trouverez sur ce lien une analyse simple mais efficace.
Il est à noter que Yahoo a massivement investi dans le projet Hadoop. La société utilise Hadoop pour sa page d’accueil (publicités ciblées, contenus adaptés, le « top recherche » des utilisateurs…) depuis 2006 et fut l’un des plus grands utilisateurs, testeurs et contributeurs du projet. Yahoo possède à ce jour le plus grand nombre de machines Hadoop avec plus de 42.000 nœuds. À titre d’exemple, Yahoo a monté un serveur Hadoop de 2000 nœuds afin de trier vingt téraoctets de données. La tâche a pris 2 heures et 30 minutes (référence).

Vous trouverez sur cette page : PoweredBy, la liste des entreprises et institutions publiques qui utilisent Hadoop. Sur ce lien sont référencés les spécifications des machines Hadoop en terme de nombre de nœuds.
Concernant les usages, ils sont relativement variés. Les propos qui vont suivre sont basés sur ce livre en libre accès : Hadoop Illuminated. Je vous invite également à consulter le Hadoop User Group qui contient de très bonnes vidéos sur des retours d’expérience sur Apache Hadoop dans les entreprises françaises.
- Santé : des chercheurs d’un hôpital pour enfants à Los Angeles (lien) stockent et analysent des données issues des capteurs sensoriels. Apache HDFS est utilisée pour ses capacités de stockage (environ un téraoctet par jour) et sa facilité de scalabilité à moindre coût. L’entreprise NextBio analyse de grandes quantités de données sur des génomes humains (lien). L’analyse est réalisée par des batches MapReduce et le stockage (plusieurs téraoctets) est effectué par Hbase, la base de données clé/valeur.
- Télécommunication : Nokia collecte et analyse de grandes quantités de données (un téraoctet par jour) issues des téléphones portables de sa marque (lien).
- Énergie : des travaux sont en cours chez EDF pour s’intéresser à la modélisation, l’analyse et la prévision des consommations électriques en captant les informations de compteurs intelligents. Une solution à base d’Hadoop est utilisée pour le stockage et l’analyse de courbes de charge (séries temporelles) (lien 1 et lien 2).
- Transport : US Xpress, une importante société de transport routier aux États-Unis utilise Apache Hadoop pour stocker les données de capteurs transmises par leur flotte de véhicules (données de géolocalisation, par exemple). L’analyse permet d’optimiser le déplacement de véhicules dans le but d’économiser sur le coût du carburant (lien). Une expérimentation a également donné lieu à l’utilisation d’Apache Hadoop pour la résolution du problème du voyageur de commerce dont le but est « étant donné n points (des « villes ») et les distances séparant chaque point, trouver un chemin de longueur totale minimale qui passe exactement une fois par chaque point et revienne au point de départ » (wikipedia). Il est intéressant de voir 1) la décomposition du problème en MapReduce et 2) que Hadoop n’a pu proposer des solutions approchées de manière efficace.
- Vente : Etsy, un site de e-commerce analyse les gros volumes des données de logs pour déterminer le comportement utilisateur ou les recommandations de recherche (lien).
- Images et vidéos : SkyBox, qui fournit un système pour capturer des vidéos et des images satellite n’importe où sur Terre utilise Hadoop pour effectuer des traitements en parallèle sur les images. Le traitement se fait via des algorithmes écrits en C++, les développeurs de la société ont réalisé un framework permettant d’exécuter du code natif à partir du framework MapReduce écrit en Java (lien).
Hadoop Distributed File System (HDFS)
HDFS (Hadoop Distributed File System) reprend de nombreux concepts proposés par des systèmes de fichiers classiques comme ext2 pour Linux ou FAT pour Windows. Nous retrouvons donc la notion de blocs (la plus petite unité que l’unité de stockage peut gérer), les métadonnées qui permettent de retrouver les blocs à partir d’un nom de fichier, les droits ou encore l’arborescence des répertoires.
Toutefois, HDFS se démarque d’un système de fichiers classique pour les principales raisons suivantes.
- HDFS n’est pas solidaire du noyau du système d’exploitation. Il assure une portabilité et peut être déployé sur différents systèmes d’exploitation. Un des inconvénients est de devoir solliciter une application externe pour monter une unité de disque HDFS.
- HDFS est un système distribué. Sur un système classique, la taille du disque est généralement considérée comme la limite globale d’utilisation. Dans un système distribué comme HDFS, chaque nœud d’un cluster correspond à un sous-ensemble du volume global de données du cluster. Pour augmenter ce volume global, il suffira d’ajouter de nouveaux nœuds. On retrouvera également dans HDFS, un service central appelé Namenode qui aura la tâche de gérer les métadonnées.
- HDFS utilise des tailles de blocs largement supérieures à ceux des systèmes classiques. Par défaut, la taille est fixée à 64 Mo. Il est toutefois possible de monter à 128 Mo, 256 Mo, 512 Mo voire 1 Go. Alors que sur des systèmes classiques, la taille est généralement de 4 Ko, l’intérêt de fournir des tailles plus grandes permet de réduire le temps d’accès à un bloc. Notez que si la taille du fichier est inférieure à la taille d’un bloc, le fichier n’occupera pas la taille totale de ce bloc.
- HDFS fournit un système de réplication des blocs dont le nombre de réplications est configurable. Pendant la phase d’écriture, chaque bloc correspondant au fichier est répliqué sur plusieurs nœuds. Pour la phase de lecture, si un bloc est indisponible sur un nœud, des copies de ce bloc seront disponibles sur d’autres nœuds.
Namenode
Un Namenode est un service central (généralement appelé aussi maître) qui s’occupe de gérer l’état du système de fichiers. Il maintient l’arborescence du système de fichiers et les métadonnées de l’ensemble des fichiers et répertoires d’un système Hadoop. Le Namenode a une connaissance des Datanodes (étudiés juste après) dans lesquels les blocs sont stockés. Ainsi, quand un client sollicite Hadoop pour récupérer un fichier, c’est via le Namenode que l’information est extraite. Ce Namenode va indiquer au client quels sont les Datanodes qui contiennent les blocs. Il ne reste plus au client qu’à récupérer les blocs souhaités.
Toutes ces métadonnées, hormis la position des blocs dans les Datanodes, sont stockées physiquement sur le disque système dans deux types de fichiers spécifiques edits_xxx et fsimage_xxx.
La connaissance de la position des blocs dans les Datanodes est reconstruite à chaque démarrage du Namenode dans un mode appelé safe mode. Pendant le safe mode, l’écriture sur HDFS est impossible, le Namenode charge les fichiers edits_xxx et fsimage_xxx et attend le retour des Datanodes sur la position des blocs. Une fois toutes les opérations réalisées, le safe mode est relâché et l’accès en écriture est de nouveau autorisé. Soyez patient sur la durée du safe mode. Celui-ci peut être très long si vous avez beaucoup de fichiers à traiter.
Comme vous l’aurez remarqué, le Namenode charge tout en mémoire. Cela devient donc problématique si vous avez énormément de petits fichiers à gérer. D’après la documentation officielle de Cloudera, chaque fichier, répertoire et bloc dans HDFS est représenté comme un objet dans la mémoire et occupe 150 octets. Si, par exemple, vous avez 10 millions de fichiers à gérer, le Namenode devra disposer d’un minimum de 1,5 Go de mémoire. C’est donc un point important à prendre en compte lors du dimensionnement de votre cluster. Le Namenode est relativement gourmand en mémoire.
Secondary Namenode
Le Namenode dans l’architecture Hadoop est un point unique de défaillance (Single Point of Failure en anglais). Si ce service est arrêté, il n’y a pas moyen de pouvoir extraire les blocs d’un fichier donné. Pour répondre à cette problématique, un Namenode secondaire appelé Secondary Namenode a été mis en place dans l’architecture Hadoop. Son fonctionnement est relativement simple puisque le Namenode secondaire vérifie périodiquement l’état du Namenode principal et copie les métadonnées via les fichiers edits_xxx et fsimage_xxx. Si le Namenode principal est indisponible, le Namenode secondaire prend sa place.
Datanode
Précédemment, nous avons vu qu’un Datanode contient les blocs de données. Les Datanodes sont sous les ordres du Namenode et sont surnommés les Workers. Ils sont donc sollicités par les Namenodes lors des opérations de lecture et d’écriture. En lecture, les Datenodes vont transmettre au client les blocs correspondant au fichier à transmettre. En écriture, les Datanodes vont retourner l’emplacement des blocs fraîchement créés. Les Datanodes sont également sollicités lors de l’initialisation du Namenode et aussi de manière périodique, afin de retourner la liste des blocs stockés.
MapReduce
MapReduce adresse deux choses. La première concerne le modèle de programmation MapReduce, étudié dans cette section. La seconde concerne le framework d’implémentation MapReduce, étudié dans le prochain article. Pour ce dernier, nous nous focaliserons sur les différentes API proposées par Apache Hadoop pour développer un programme MapReduce à partir du langage Java.
Le modèle de programmation fournit un cadre à un développeur afin d’écrire une fonction de Map et de Reduce. Tout l’intérêt de ce modèle de programmation est de simplifier la vie du développeur. Ainsi, ce développeur n’a pas à se soucier du travail de parallélisation et de distribution du travail, de récupération des données sur HDFS, de développements spécifiques à la couche réseaux pour la communication entre les nœuds, ou d’adapter son développement en fonction de l’évolution de la montée en charge (scalabilité horizontale, par exemple). Ainsi, le modèle de programmation permet au développeur de ne s’intéresser qu’à la partie algorithmique. Il transmet alors son programme MapReduce développé dans un langage de programmation au framework Hadoop pour l’exécution.
Autre chose avant de continuer, le terme de « job » MapReduce est couramment utilisé dans la littérature. Celui-ci concerne une unité de travail que le client souhaite réaliser. Cette unité est constituée de données d’entrée (contenues dans HDFS), d’un programme MapReduce (implémentation des fonctions map et reduce) et de paramètres d’exécution. Hadoop exécute ce job en le subdivisant en deux tâches : les tâches de Map et les tâches de Reduce.
Voyons maintenant le principe général de MapReduce, puis nous détaillerons son fonctionnement distribué dans Hadoop.
MapReduce : principe général
Les concepts de map et de reduce ne sont pas nouveaux puisqu’ils ont été empruntés aux langages fonctionnels, sauf que Google les a efficacement propulsés dans l’univers du calcul distribué et du grand volume de données. Ils sont utilisés pour implémenter des opérations de base sur les données comme le tri, le filtrage, la projection, l’agrégation ou le regroupement.
Pour expliquer les concepts de map et de reduce, partons de l’exemple du compteur de mots fréquemment utilisés, avec une légère variante. Tous les mots sont comptabilisés à l’exception du mot « se ». Ci-dessous, le fichier exemple.txt présente un jeu de données comportant une seule ligne.
1
2
voiture la le elle de elle la se la maison voiture
...
On distingue clairement sur la première ligne que le mot la est répété trois fois et que le mot voiture est répété deux fois.
La figure ci-dessous énumère les différentes étapes qui seront présentées par la suite.
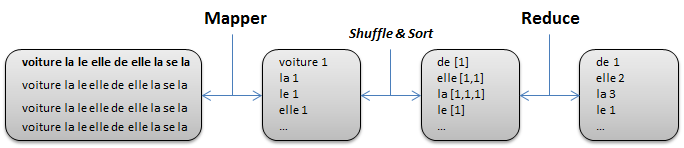
Fonction map
La fonction map s’écrit de la manière suivante : map(clé1, valeur1) → List(clé2, valeur2). À partir d’un couple clé/valeur, la fonction map retourne un ensemble de nouveaux couples clé/valeur. Cet ensemble peut être vide, d’une cardinalité un ou plusieurs.
Dans notre exemple, la clé d’entrée correspond au numéro de ligne dans le fichier et la valeur vaut voiture la le elle de elle la se la maison voiture.
Le résultat de la fonction map est donné ci-dessous.
1
2
3
4
5
6
7
8
9
10
(voiture,1)
(la,1)
(le,1)
(elle,1)
(de,1)
(elle,1)
(la,1)
(la,1)
(maison,1)
(voiture,1)
Nous remarquons que la fonction map retourne bien une liste de couples clé/valeur et que la clé utilisée à l’entrée de la fonction map n’est pas exploitée. Comme prévu, nous constatons que le mot « se » n’apparaît pas à la sortie de la fonction.
1
2
3
4
5
6
7
8
9
10
11
12
13
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
String string = itr.nextToken();
if (!string.equals("se")) {
Text word = new Text();
word.set(string);
context.write(word, new IntWritable(1));
}
}
}
}
Sans détailler l’API, puisque nous le ferons dans le prochain article, à la ligne 3 un StringTokenizer est utilisé pour découper la chaîne de caractères. Pour chaque mot obtenu, nous créons un couple dont la clé est le mot et la valeur vaut 1. Notez qu’à la ligne 6, nous effectuons un filtre pour exclure les instances du mot « se ».
Avant de présenter la fonction reduce, deux opérations intermédiaires doivent être exécutées pour préparer la valeur de son paramètre d’entrée. La première opération appelée shuffle permet de grouper les valeurs dont la clé est commune. La seconde opération appelée sort permet de trier par clé. À la différence des fonctions map et reduce, shuffle et sort sont des fonctions fournies par le framework Hadoop. Il n’y a donc pas à les implémenter.
Ainsi, après l’exécution des fonctions shuffle et sort le résultat de l’exemple est le suivant.
1
2
3
4
5
6
(de,[1])
(elle,[1,1]
(la,[1,1,1])
(le,[1])
(maison,[1])
(voiture,[1,1])
Fonction reduce
La fonction reduce s’écrit de la manière suivante : reduce(clé2, List(valeur2)) → List(valeur2). À partir des groupes de valeurs associées à une clé, la fonctions reduce retourne généralement une valeur ou aucune, bien qu’il soit possible de retourner plus d’une valeur.
Suite à l’appel de la fonction reduce, le résultat de l’exemple est le suivant.
1
2
3
4
5
6
7
(de,1)
(elle,2)
(la,3)
(le,1)
(maison,1)
(voiture,2)
Nous constatons que pour chaque clé, la fonction reduce effectue une somme de chaque élément de la liste.
1
2
3
4
5
6
7
8
9
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable current : values) {
sum += current.get();
}
context.write(key, new IntWritable(sum));
}
}
Rien de bien méchant dans l’implémentation de la fonction reduce. Le parcours des éléments de la liste de valeurs se fait à la ligne 4 depuis l’itérateur values. Pour chaque élément de la liste, une somme est effectuée à la ligne 5.
MapReduce dans Hadoop
Intéressons-nous maintenant à voir comment le modèle de programmation MapReduce est exploité dans le framework Hadoop. Je tiens avant tout à préciser que je ne détaillerai pas le fonctionnement du nouveau système YARN pour la gestion de jobs MapReduce, car je n’ai pas encore assez de recul. Je peux juste faire remarquer que les composants JobTracker et TaskTrackers ont été remplacés par les composants ResourceManager, NodeManager et ApplicationMaster.
Étape du découpage des données (split)
La première étape concerne le découpage (split) des données. Cette étape est à la charge du framework qui se base sur le format des données. La taille de chaque découpage est fixe et généralement identique à la taille d’un bloc HDFS (64 Mo par défaut).
En s’appuyant sur l’exemple du compteur de mots fréquemment utilisés, le découpage consistera à réaliser des morceaux de 64 Mo qui contiendront chacun une liste de clé/valeur où la clé sera l’offset d’une ligne du fichier et la valeur le contenu de cet offset (voiture la le elle de elle la se la maison voiture).
Étape Map
Hadoop crée pour chaque découpage de données une tâche de Map qui exécutera la fonction map développée en conséquence. Chaque découpage de données n’est traité que par une seule tâche de Map.
Précisons que ce n’est pas la donnée qui est transportée vers le programme, mais l’inverse. Cela permet de pouvoir profiter d’une optimisation appelée optimisation de proximité de la donnée (Data Locality Optimization en anglais). Hadoop va donc tenter de trouver le nœud le plus proche contenant la donnée pour y transférer la fonction Map.
Une fois la tâche Map terminée, le résultat de la fonction n’est pas stocké sur le système HDFS, mais sur le système de fichier local du nœud. En effet, il s’agit d’un résultat intermédiaire et qui n’a pas besoin d’être stocké de manière sécurisée via la réplication des blocs HDFS. Dans le cas d’une anomalie sur l’exécution de la tâche (nœud qui devient inaccessible par exemple), Hadoop est informé et pourra demander sa rééxécution.
Étape Reduce
Hadoop ne lance les tâches de Reduce qu’une fois que toutes les tâches de Map sont terminées. Notez que le nombre de tâches de Reduce n’est pas fonction de la taille des données en entrée mais est spécifié en paramètre de configuration d’exécution du job. C’est donc un paramètre qui peut être modifié. Par défaut, le nombre de tâches de Reduce est 1.
L’entrée de la fonction reduce correspond à la sortie de l’ensemble des fonctions map. Comme la tâche de Reduce ne profite pas d’optimisation de proximité comme cela est fait pour la tâche de Map, les données de sortie de la fonction map sont transférées via le réseau vers le nœud où la tâche de Reduce est réalisée.
Chaque tâche de Reduce produit un fichier de sortie qui sera stocké, cette fois, dans le système de fichiers HDFS. Le format du nom du fichier produit est de la forme suivante : part-r-XXXX où XXXX est le numéro de la tâche de Reduce commençant par 0. Dans notre exemple, il y aura donc un seul fichier, car une seule tâche de Reduce, qui portera le nom part-r-0000.
1
2
3
4
5
6
de 1
elle 2
la 3
le 1
maison 1
voiture 2
Étape Combiner (facultative)
Précédemment, nous avons vu que les données de sortie de la fonction map étaient transférées par le réseau vers le nœud où s’effectuera la tâche de Reduce. Bien entendu, cela peut avoir un impact sur les performances car les données à transmettre peuvent être volumineuses. Pour répondre à ce problème, une autre optimisation consiste à utiliser une fonction dite Combiner en sortie directe de la fonction map. Le Combiner a le même comportement que la tâche Reduce et il s’appuie sur la même API.
Quand un Combiner est utilisé, la sortie de la fonction map n’est pas écrite sur le système de fichiers local. Un traitement en mémoire est réalisé afin de regrouper les valeurs par clé (identique à shuffle et sort).
Considérons la sortie d’une première tâche Map (identique à notre précédent exemple).
1
2
3
4
5
6
7
8
9
10
(voiture,1)
(la,1)
(le,1)
(elle,1)
(de,1)
(elle,1)
(la,1)
(la,1)
(maison,1)
(voiture,1)
Considérons maintenant la sortie d’une seconde tâche Map.
1
2
3
(voiture,1)
(voiture,1)
(voiture,1)
Après application de la fonction Combiner sur la sortie de la première tâche Map, le résultat attendu est le suivant.
1
2
3
4
5
6
(de,1)
(elle,2)
(la,3)
(le,1)
(maison,1)
(voiture,2)
De même, après application de la fonction Combiner sur la sortie de la seconde tâche Map, le résultat attendu est le suivant.
1
(voiture,3)
Par conséquent, l’entrée de la fonction reduce sera celui-ci.
1
2
3
4
5
6
(de,[1])
(elle,[2])
(la,[3])
(le,[1])
(maison,[1])
(voiture,[2,3])
Écosystème Hadoop : une foire aux sous-projets
Comme expliqué précédemment, Hadoop est un système distribué orienté batch, taillé pour le traitement de jeux de données volumineux. Les utilisateurs d’Hadoop se retrouvent alors à manipuler le système de fichiers HDFS ou à développer des programmes MapReduce bas niveau en partant souvent de rien. Des sous-projets à Hadoop sont nés de ce constat et offrent des mécanismes et fonctionnalités qui simplifient la manipulation et le traitement des jeux de données volumineux. Nous en présenterons brièvement quelques-uns dans cette section. Une liste complète peut être trouvée ici : Bigdata Ecosystem
HBase
![]()
HBase permet l’intégration à Hadoop d’un système de stockage par clé/valeur appelé couramment stockage binaire ou key/value store en anglais.
Ce sous-projet à Hadoop est également inspiré par le projet BigTable de Google.
Hive
![]()
Hive crée une base de données relationnelle dans le système de fichiers HDFS. Le projet permet aux développeurs d’écrire des requêtes, dans un langage proche de SQL appelé HiveQL, qui sont ensuite traduites comme des programmes MapReduce sur le cluster. L’avantage est de pouvoir fournir un langage que les développeurs connaissent pour l’écriture des programmes MapReduce.
Pig
![]()
Le projet Pig se positionne comme Hive dans le sens où il fournit aux développeurs un langage de haut niveau (un DSL) dédié à l’analyse de gros volumes de données. Il s’adresse alors aux développeurs habitués à faire des scripts via Bash ou Python par exemple. Par ailleurs, Pig est extensible dans le sens où, si une fonction n’est pas disponible, il est possible de l’enrichir via des développements spécifiques dans un langage bas niveau (Java, Python…).
Dans le même ordre d’idées que le projet Pig, il y a Scalding qui puise la puissance du langage Scala pour développer ses programmes MapReduce.
Sqoop
![]()
Sqoop est un projet qui aide à dialoguer avec des systèmes de gestion de base de données relationnelle vers Hadoop. Le projet permet d’importer et d’exporter des données de ou vers une base de données.
Mahout

Mahout fournit des implémentations d’algorithmes pour faire de l’informatique décisionnelle. Il fournit par exemple des algorithmes pour faire du partitionnement de données ou de la classification automatique dans un environnement MapReduce.
Jeux de données
Le problème pour tester Apache Hadoop est de disposer de jeux de données réalistes. Je vous propose, dans cette section, un recueil de sites qui proposent différents types de données.
- The National Bureau of Economic Research : regroupe plus de trois millions de brevets américains déclarés pendant la période de janvier 1963 à décembre 1999.
- Données publiques depuis Amazon Web Services : regroupe un ensemble de données rendues publiques comme NASA NEX, une collection d’ensembles de données portant sur les sciences de la Terre entretenue par la NASA, Common Crawl Corpus, un corpus de données d’indexation Web composé de plus de cinq milliards de pages Web, ou encore des données du recensement des États-Unis pour la période 1980, 1990 et 2000.
- ClueWeb09 : contient plus d’un milliard de pages Web dédiées à la recherche sur des technologies du langage humain.
- IMDB : un sous-ensemble de la base de données liée au monde du cinéma.
- National Climatic Data Center : données concernant le climat proposées par la National Oceanic and Atmospheric Administration, une institution gouvernementale des États-Unis.
- Grouplens : groupe de recherche, dans le domaine de systèmes de recommandation et d’interaction homme-machine, qui a collecté de grands volumes de données comme par exemple sur des classements de films auprès d’utilisateurs.
- DBPedia : version structurée de Wikipédia
Conclusion et perspectives
Cet article s’est intéressé à présenter les généralités d’Hadoop, HDFS et le modèle de programmation MapReduce. La présentation des concepts était obligatoire afin de mieux cerner les articles plus techniques qui vont suivre.
Dans le prochain tutoriel de cette série, nous montrerons comment installer et configurer un cluster simple nœud avec Cloudera CDH. L’intérêt d’un cluster simple nœud a pour vocation d’être pédagogique (comprendre les fichiers de configuration, les outils de base…) et de disposer d’un environnement de développement pour tester ses développements de programmes MapReduce.
Cet article est disponible sur le site de Developpez.com.
Je tiens à remercier, Stéphane Jean pour son avis constructif ainsi que phanloga et Youness Bazhar pour la relecture orthographique.
Références
Cours, Articles
- Explication sur Map/Reducce : http://wiki.apache.org/hadoop/HadoopMapReduce.
- Des jeux de données pour stresser son cluster : http://www.hadooplessons.info/2013/06/data-sets-for-practicing-hadoop.html.
- Le site du Hadoop User Group français : http://hugfrance.fr/.
- Un billet qui présente les prérequis avant de foncer vers Hadoop : http://blog.octo.com/votre-premier-projet-hadoop/.
- Hadoop sur Wikipédia : http://en.wikipedia.org/wiki/Apache_Hadoop.
- Supports de cours sur Hadoop : http://courses.coreservlets.com/Course-Materials/pdf/hadoop/.
- Des billets sur Hadoop : http://blog.inovia-conseil.fr/?cat=27.
- Une présentation sur HDFS : http://fr.slideshare.net/hugfrance/introduction-hdfs.
- Une série de billets sur Hadoop : http://www.bigdataplanet.info/search/label/Hadoop-Tutorial.
- Un livre Open Source sur MapReduce : http://lintool.github.io/MapReduceAlgorithms.
- Un billet qui présente les nouveautés Hadoop 2 : http://strata.oreilly.com/2014/01/an-introduction-to-hadoop-2-0-understanding-the-new-data-operating-system.html.
- Gartner et le Big Data: http://www.gartner.com/technology/research/big-data/.
Livres
- Hadoop Illuminated : http://hadoopilluminated.com/.
- Hadoop In Pratice : http://www.manning.com/holmes/.
- Hadoop Operations : http://shop.oreilly.com/product/0636920025085.do.
- Hadoop The Definitive Guide : http://shop.oreilly.com/product/0636920021773.do.
- Hadoop In Action : http://www.manning.com/lam/.
Je suis Mickaël BARON Ingénieur de Recherche en Informatique à l'ISAE-ENSMA et membre du laboratoire LIAS le jour
Veilleur Technologique la nuit
#Java #Container #VueJS #Services #WebSemantic

Derniers articles et billets