Introduction à Apache Hadoop : installation et configuration d'un cluster Hadoop simple nœud (partie 2)
- Téléchargement et versions
- Installation et exécution d’un cluster simple nœud
- Manipulation du contenu HDFS
- Exécution d’un exemple de job MapReduce
- Administrer avec Hue
- Conclusion et perspectives
- Bonus
- Références
Ce deuxième article s’intéresse à l’installation et la configuration d’un cluster Hadoop simple nœud en utilisant la distribution CDH 5 fournie par Cloudera. Nous décrirons comment réaliser une telle installation dans un système virtualisé Linux. Bien entendu, Hadoop n’a d’intérêt que s’il est utilisé dans un cluster composé de plusieurs machines. En effet, utiliser Hadoop dans un environnement simple nœud, comme nous allons le faire, n’a de sens que pour tester la configuration de l’installation ou fournir un environnement de développement MapReduce.
Nous n’aborderons pas dans cet article le développement de programmes MapReduce en Java. Cet aspect sera présenté dans le prochain article. Nous utiliserons donc les programmes MapReduce fournis par la distribution Hadoop.
Mes articles consacrés à Hadoop sont décrits ci-dessous :
- Généralités sur HDFS et MapReduce ;
- Installation et configuration d’un cluster simple nœud avec Cloudera CDH 5 ;
- Installation, supervision et performance d’un cluster multi-nœud avec Cloudera CDH 5.
Je tiens à préciser que je ne suis pas un spécialiste d’Hadoop. Ces articles sont le résultat d’une veille technologique. Ils seront sûrement améliorés au fur et à mesure de mes différentes découvertes et exploitation d’Hadoop lors de cas réels.
L’objectif visé par ces articles est de démystifier Apache Hadoop et de tenter de rendre sa compréhension aussi facile qu’un jeu d’enfant.
Téléchargement et versions
Pour télécharger Hadoop deux solutions sont disponibles. La première solution est d’utiliser la version proposée par la fondation Apache. Cette version est celle de référence et contient le noyau et quelques interfaces d’aministration très simplifiée. La seconde solution est d’utiliser les distributions fournies par des entreprises qui font du service autour d’Hadoop. Comme il y a une valeur ajoutée non négligeable, ces distributions fournissent des services payants. Sans être exhaustif, voici trois sociétés qui font de Hadoop leur spécialité.
- Cloudera : http://www.cloudera.com/.
- Hortonworks : http://hortonworks.com/.
- MapR Technologies : http://www.mapr.com/.
Dans le cadre de cet article, j’utiliserai la distribution de la compagnie Cloudera. Cette distribution a l’avantage d’être gratuite pour Cloudera Standard. Elle fournit également des outils d’administration supplémentaires qui facilitent son usage.
Par ailleurs, si l’on consulte le site de la fondation Apache, on se retrouve avec quatre versions majeures Hadoop. À l’écriture de cet article et de mes premières expérimentations, il s’agissait des versions 0.23.X, 1.2.X, 2.2.X et 2.X.X. Les trois premières versions correspondent à des versions stables et aptes à passer en production. La dernière est la version en cours. Puisque je n’ai pas d’antériorité avec Hadoop, j’ai pris le risque de la nouveauté en utilisant la version majeure 2.3.X fournie avec la distribution de Cloudera.
Dans le cas de Cloudera, l’alignement des versions avec celle d’Hadoop n’est pas identique. La version actuelle de Cloudera est la 5 ce qui correspond en gros à la version 2.3.X de la fondation Apache. Dans la suite de ce tutoriel, nous utiliserons Cloudera 5 Standard.
À la différence de la version proposée par Apache où il est nécessaire de télécharger une archive, la version Hadoop de Cloudera fournit une installation via des packages. Intéressons-nous donc, dans la suite, à voir comment installer Hadoop avec la distribution Cloudera.
Installation et exécution d’un cluster simple nœud
Dans cette section, nous expliquerons l’installation, la configuration et l’exécution d’un cluster simple nœud pour une distribution Linux.
L’installation se fera avec la distribution Linux Ubuntu 12.04 Precise 64 en mode serveur (ne contient pas de serveur X). J’utiliserai la virtualisation du système Linux avec VirtualBox depuis mon Windows 7.
Dans la section Bonus nous expliquerons comment mettre en place cette virtualisation avec VirtualBox et Vagrant et comment automatiser l’installation des outils avec Puppets.
Prérequis
Nous présentons dans cette section, les différents prérequis logiciels pour reproduire les expérimentations de cet article.
Mise à jour système
Avant toutes installations de nouveaux paquets, mettez à jour le cache des paquets sur votre machine. La commande suivante téléchargera la nouvelle liste des paquets proposés par le dépôt.
1
sudo apt-get update
Java
Hadoop nécessite une version Java 7 ou au moins Java 6. Veuillez consulter cette page pour connaître les compatibilités de la plate-forme Java avec Apache Hadoop.
Pour ce tutoriel, la version 7 de Java sera utilisée via la distribution OpenJDK. Voir commande ci-dessous pour installer OpenJDK 7 sur un Linux.
sudo apt-get install openjdk-7-jdk
Après l’installation, assurez-vous que la version Java est correctement installée.
1
2
3
4
$ java -version
java version "1.7.0_25"
OpenJDK Runtime Environment (IcedTea 2.3.10) (7u25-2.3.10-1ubuntu0.12.04.2)
OpenJDK 64-Bit Server VM (build 23.7-b01, mixed mode)
Groupe et utilisateur Hadoop
Nous emploierons un utilisateur Hadoop spécifique pour exécuter un nœud Hadoop. Bien que celui-ci ne soit pas requis, il est fortement recommandé de séparer les installations des logiciels afin de garantir les problèmes de sécurité et de permissions.
1
2
sudo addgroup hadoop
sudo adduser --ingroup hadoop hduser
À la suite de la dernière instruction, il vous sera demandé un mot de passe, saisir hduser. Pour les autres informations demandées donner les valeurs par défaut.
Un utilisateur hduser avec le mot de passe hduser sera créé et ajouté au groupe hadoop.
Connectez-vous avec ce nouvel utilisateur.
1
su hduser
Configuration SSH
Hadoop nécessite un accès SSH pour gérer les différents nœuds. Bien que nous soyons dans une configuration simple nœud, nous avons besoin de configurer l’accès vers localhost pour l’utilisateur hduser que nous venons de créer précédemment.
Avant tout, nous devons générer une clé SSH pour l’utilisateur hduser.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$ ssh-keygen -t rsa -P ""
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hduser/.ssh/id_rsa):
Created directory '/home/hduser/.ssh'.
Your identification has been saved in /home/hduser/.ssh/id_rsa.
Your public key has been saved in /home/hduser/.ssh/id_rsa.pub.
The key fingerprint is:
80:36:b8:8d:04:32:d2:d2:d8:ef:02:ff:01:a4:c5:63 hduser@precise64
The key's randomart image is:
+--[ RSA 2048]----+
|=* |
|=oE. . |
| *oo+ . |
|o..=.. . |
| ooo. S |
| o o |
| o . |
| . |
| |
+-----------------+
Cette commande va créer une clé RSA avec un mot de passe vide. Dans notre cas de virtualisation, l’absence de mot de passe n’a pas d’importance. Assurez-vous d’en fixer un si votre serveur est accessible depuis l’extérieur.
Vous devez ensuite autoriser l’accès au SSH de la machine avec cette nouvelle clé fraîchement créée.
1
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
La dernière chose à réaliser est de tester la connexion SSH à partir de l’utilisateur hduser.
1
2
3
4
5
6
7
8
9
10
11
$ ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ECDSA key fingerprint is 11:5d:55:29:8a:77:d8:08:b4:00:9b:a3:61:93:fe:e5.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 12.04 LTS (GNU/Linux 3.2.0-23-generic x86_64)
* Documentation: https://help.ubuntu.com/
Welcome to your Vagrant-built virtual machine.
Last login: Sat Dec 14 20:19:33 2013 from 127.0.0.1
hduser@precise64:~$
Installation
La distribution Cloudera fournit une installation par package assez souple. Il est donc possible d’ajouter les différents composants de la distribution Hadoop via le gestionnaire de packages.
Depuis la racine du compte Vagrant, télécharger le paquet Debian suivant.
1
wget http://archive.cloudera.com/cdh5/one-click-install/precise/amd64/cdh5-repository_1.0_all.deb
Puis, installer ce paquet Debian.
1
sudo dpkg -i cdh5-repository_1.0_all.deb
Ajouter la clé public GPC de Cloudera à votre entrepôt de paquets Debian.
1
curl -s http://archive.cloudera.com/cdh5/ubuntu/precise/amd64/cdh/archive.key | sudo apt-key add -
Penser à faire une mise à jour du cache des paquets de votre système.
1
sudo apt-get update
Votre système est maintenant prêt pour aller récupérer les paquets directement sur le serveur de Cloudera.
Le premier paquet à installer sera le gestionnaire de ressources (ResourceManager).
1
sudo apt-get install hadoop-yarn-resourcemanager
L’installation du paquet crée un service /etc/init.d/hadoop-yarn-resourcemanager et le démarre.
Installer ensuite le paquet lié à la gestion des métadonnées (NameNode).
1
sudo apt-get install hadoop-hdfs-namenode
L’installation du paquet hadoop-hdfs-namenode crée un service /etc/init.d/hadoop-hdfs-namenode et tente de le démarrer mais échoue. L’erreur est liée à un paramètre manquant dans un fichier de configuration. Nous y reviendrons dans la prochaine section.
1
2
3
4
5
...
Setting up hadoop-hdfs-namenode (2.3.0+cdh5.0.1+567-1.cdh5.0.1.p0.46~precise-cdh5.0.1) ...
* Starting Hadoop namenode:
starting namenode, logging to /var/log/hadoop-hdfs/hadoop-hdfs-namenode-precise64.out
invoke-rc.d: initscript hadoop-hdfs-namenode, action "start" failed.
Installer les packages pour gérer les données (DataNode), le gestionnaire de nœuds (NodeManager) et finalement MapReduce.
1
sudo apt-get install hadoop-yarn-nodemanager hadoop-hdfs-datanode hadoop-mapreduce
Les services /etc/init.d/hadoop-hdfs-datanode et /etc/init.d/hadoop-yarn-nodemanager sont créés. On constate depuis la sortie console, que le service de gestion des données échoue à son démarrage. Cette erreur est provoquée puisque le système de fichiers HDFS n’a pas encore été formaté.
1
2
3
4
5
6
7
8
9
...
Setting up hadoop-hdfs-datanode (2.3.0+cdh5.0.1+567-1.cdh5.0.1.p0.46~precise-cdh5.0.1) ...
* Starting Hadoop datanode:
starting datanode, logging to /var/log/hadoop-hdfs/hadoop-hdfs-datanode-vagrantmanualcloudera5ubuntu64.out
invoke-rc.d: initscript hadoop-hdfs-datanode, action "start" failed.
Setting up hadoop-mapreduce (2.3.0+cdh5.0.1+567-1.cdh5.0.1.p0.46~precise-cdh5.0.1) ...
Setting up hadoop-yarn-nodemanager (2.3.0+cdh5.0.1+567-1.cdh5.0.1.p0.46~precise-cdh5.0.1) ...
* Starting Hadoop nodemanager:
starting nodemanager, logging to /var/log/hadoop-yarn/yarn-yarn-nodemanager-vagrantmanualcloudera5ubuntu64.out
Finalement installer le paquet dédié au serveur d’historisation des informations des jobs MapReduce.
1
sudo apt-get install hadoop-mapreduce-historyserver
À la suite de l’installation des packages de Cloudera, les utilisateurs yarn, hdfs et mapred, ont été créés et placés dans le groupe hadoop.
Fichiers de configuration Hadoop
Tous les fichiers de configuration d’Hadoop sont disponibles dans le répertoire /etc/hadoop/conf.
Les fichiers de configuration d’Hadoop fonctionnent sur le principe de clé/valeur : la clé correspondant au nom du paramètre et valeur à la valeur assignée à ce paramètre. Ces fichiers de configuration utilisent le format XML. Les nouveaux paramètres sont à ajouter entre la balise <configuration> … </configuration>.
Je ne peux être exhaustif sur les modifications à apporter sur ces fichiers de configuration. Je me limiterai donc aux paramètres de base pour exécuter un cluster Hadoop d’un nœud. Pour plus d’informations sur les paramètres autorisés, je vous invite à consulter les liens que je donnerai pour chaque fichier modifié.
core-site.xml
Depuis le fichier /etc/hadoop/conf/core-site.xml modifier le contenu afin d’obtenir le résultat ci-dessous :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<description>The name of the default file system.</description>
</property>
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
</configuration>
La propriété fs.defaultFS permet de spécifier le nom du système de fichier. Ainsi tous les répertoires et fichiers HDFS sont préfixés par hdfs://localhost:9000.
Les deux autres paramètres hadoop.proxyuser.hue.hosts et hadoop.proxyuser.hue.groups serviront pour les besoins de configuration de Hue.
Enfin, je tiens à préciser que la propriété hadoop.tmp.dir pointe par défaut sur le répertoire /tmp/hadoop-${user.name}. Vous retrouvez donc dans ce répertoire (/tmp/hadoop-${user.name}) tous les sous-répertoires nécessaires au stockage des données pour Hadoop (Namenode, Datanode…).
hdfs-site.xml
Le fichier /etc/hadoop/conf/hdfs-site.xml contient les paramètres spécifiques au système de fichiers HDFS.
1
2
3
4
5
6
7
8
9
10
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
Le paramètre dfs.replication permet de préciser le nombre de réplication d’un block. La valeur sera 1 puisque notre cluster ne se compose que d’un nœud. Finalement le paramètre dfs.webhdfs.enabled permet d’activer le service Web REST HDFS. L’outil d’administration Hue en a besoin pour communiquer avec HDFS.
mapred-site.xml
Le fichier /etc/hadoop/conf/mapred-site.xml contient les paramères spécifiques à MapReduce. Depuis la version 2.x d’Hadoop avec l’arrivée de Yarn, ce fichier de configuration est épaulé par yarn-site.xml. Ainsi, si vous souhaitez utiliser Yarn comme implémentation de MapReduce, il faudra configurer le fichier mapred-site.xml comme présenté ci-dessous.
1
2
3
4
5
6
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Initialisation du système de fichier HDFS
Avant de démarrer le serveur Hadoop, vous devez formater le système de fichiers HDFS. Dans le cas de cette installation d’un cluster simple nœud, seul le système de fichiers HDFS de votre machine locale sera formatée. Pour formater, exécuter la commande suivante en prenant soin d’employer l’utilisateur hdfs puisqu’il est le seul à avoir les droits dans le répertoire /var/lib/hadoop-hdfs/cache/hdfs/dfs/name :
1
sudo -u hdfs hdfs namenode -format
L’exécution du formatage devrait ressembler à cela :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
$ sudo -u hdfs hdfs namenode -format
13/12/18 18:10:14 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = precise64/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.3.0-cdh5.0.1
STARTUP_MSG: classpath = ...
STARTUP_MSG: build = git://github.sf.cloudera.com/CDH/cdh.git -r 8e266e052e423af592871e2dfe09d54c03f6a0e8; compiled by 'jenkins' on 2014-05-06T19:02Z
STARTUP_MSG: java = 1.7.0_55
************************************************************/
14/05/23 16:12:09 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
14/05/23 16:12:09 INFO namenode.NameNode: createNameNode [-format]
14/05/23 16:12:10 WARN common.Util: Path /var/lib/hadoop-hdfs/cache/hdfs/dfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
14/05/23 16:12:10 WARN common.Util: Path /var/lib/hadoop-hdfs/cache/hdfs/dfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
Formatting using clusterid: CID-beefcf0d-d7d3-4e82-838d-b839309e02cf
14/05/23 16:12:10 INFO namenode.FSNamesystem: fsLock is fair:true
14/05/23 16:12:10 INFO namenode.HostFileManager: read includes:
HostSet(
)
14/05/23 16:12:10 INFO namenode.HostFileManager: read excludes:
HostSet(
)
14/05/23 16:12:10 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
14/05/23 16:12:10 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
14/05/23 16:12:10 INFO util.GSet: Computing capacity for map BlocksMap
14/05/23 16:12:10 INFO util.GSet: VM type = 64-bit
14/05/23 16:12:10 INFO util.GSet: 2.0% max memory 889 MB = 17.8 MB
14/05/23 16:12:10 INFO util.GSet: capacity = 2^21 = 2097152 entries
14/05/23 16:12:10 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
14/05/23 16:12:10 INFO blockmanagement.BlockManager: defaultReplication = 1
14/05/23 16:12:10 INFO blockmanagement.BlockManager: maxReplication = 512
14/05/23 16:12:10 INFO blockmanagement.BlockManager: minReplication = 1
14/05/23 16:12:10 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
14/05/23 16:12:10 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false
14/05/23 16:12:10 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
14/05/23 16:12:10 INFO blockmanagement.BlockManager: encryptDataTransfer = false
14/05/23 16:12:10 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
14/05/23 16:12:10 INFO namenode.FSNamesystem: fsOwner = hdfs (auth:SIMPLE)
14/05/23 16:12:10 INFO namenode.FSNamesystem: supergroup = supergroup
14/05/23 16:12:10 INFO namenode.FSNamesystem: isPermissionEnabled = true
14/05/23 16:12:10 INFO namenode.FSNamesystem: HA Enabled: false
14/05/23 16:12:10 INFO namenode.FSNamesystem: Append Enabled: true
14/05/23 16:12:10 INFO util.GSet: Computing capacity for map INodeMap
14/05/23 16:12:10 INFO util.GSet: VM type = 64-bit
14/05/23 16:12:10 INFO util.GSet: 1.0% max memory 889 MB = 8.9 MB
14/05/23 16:12:10 INFO util.GSet: capacity = 2^20 = 1048576 entries
14/05/23 16:12:10 INFO namenode.NameNode: Caching file names occuring more than 10 times
14/05/23 16:12:10 INFO util.GSet: Computing capacity for map cachedBlocks
14/05/23 16:12:10 INFO util.GSet: VM type = 64-bit
14/05/23 16:12:10 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB
14/05/23 16:12:10 INFO util.GSet: capacity = 2^18 = 262144 entries
14/05/23 16:12:10 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
14/05/23 16:12:10 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
14/05/23 16:12:10 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
14/05/23 16:12:10 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
14/05/23 16:12:10 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
14/05/23 16:12:10 INFO util.GSet: Computing capacity for map Namenode Retry Cache
14/05/23 16:12:10 INFO util.GSet: VM type = 64-bit
14/05/23 16:12:10 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
14/05/23 16:12:10 INFO util.GSet: capacity = 2^15 = 32768 entries
14/05/23 16:12:10 INFO namenode.AclConfigFlag: ACLs enabled? false
14/05/23 16:14:04 INFO namenode.FSImage: Allocated new BlockPoolId: BP-145195179-127.0.1.1-1400861644094
14/05/23 16:14:04 INFO common.Storage: Storage directory /var/lib/hadoop-hdfs/cache/hdfs/dfs/name has been successfully formatted.
14/05/23 16:14:04 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
14/05/23 16:14:04 INFO util.ExitUtil: Exiting with status 0
14/05/23 16:14:04 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at vagrantmanualcloudera5ubuntu64/127.0.1.1
************************************************************/
Démarrage et arrêt un serveur Hadoop
La distribution Cloudera contrairement à la distribution Apache Hadoop installe des services pour contrôler le démarrage et l’arrêt d’Hadoop. L’avantage est de pouvoir démarrer Hadoop lors du démarrage du serveur Linux.
Pour démarrer un service, je vous recommande d’utiliser la commande service à la place d’une exécution directe des scripts localisés depuis /etc/init.d.
Ainsi, pour démarrer l’ensemble des services que nous avons installé, vous devrez procéder comme suit :
1
2
3
4
5
6
7
8
9
10
11
12
$ sudo service hadoop-hdfs-namenode start
* Starting Hadoop namenode:
starting namenode, logging to /var/log/hadoop-hdfs/hadoop-hdfs-namenode-precise64.out
$ sudo service hadoop-hdfs-datanode start
* Starting Hadoop datanode:
starting datanode, logging to /var/log/hadoop-hdfs/hadoop-hdfs-datanode-precise64.out
$ sudo service hadoop-yarn-resourcemanager start
* Starting Hadoop resourcemanager:
starting resourcemanager, logging to /var/log/hadoop-yarn/yarn-yarn-resourcemanager-precise64.out
$ sudo service hadoop-yarn-nodemanager start
* Starting Hadoop nodemanager:
starting nodemanager, logging to /var/log/hadoop-yarn/yarn-yarn-nodemanager-precise64.out
Tous les logs sont disponibles dans les répertoires /var/long/hadoop-xxx. N’hésitez pas à consulter les logs si le serveur ne répond pas.
Pour s’assurer que tout fonctionne, utiliser l’outil jps pour lister les processus Java en cours d’exécution.
1
2
3
4
5
6
7
$ sudo jps -lm
13958 org.apache.hadoop.yarn.server.nodemanager.NodeManager
13855 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
13543 org.apache.hadoop.hdfs.server.datanode.DataNode
13702 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
13415 org.apache.hadoop.hdfs.server.namenode.NameNode
14332 sun.tools.jps.Jps -lm
Depuis la version 2.2.x d’Hadoop, ResourceManager remplace JobTracker.
Enfin, pour arrêter un serveur Hadoop, vous devrez utiliser les commandes suivantes pour arrêter tous les services :
1
2
3
4
5
6
7
8
9
10
11
12
$ sudo service hadoop-hdfs-namenode stop
* Stopping Hadoop namenode:
stopping namenode
$ sudo service hadoop-hdfs-datanode stop
* Stopping Hadoop datanode:
stopping datanode
$ sudo service hadoop-yarn-resourcemanager stop
* Stopping Hadoop resourcemanager:
stopping resourcemanager
$ sudo service hadoop-yarn-nodemanager stop
* Stopping Hadoop nodemanager:
stopping nodemanager
Pour vous simplifier la tâche, je vous invite à écrire deux scripts bash hadoop-start et hadoop-stop qui servent respectivement à démarrer et arrêter les services HDFS et Yarn. Ces deux fichiers pourront être localisés dans le répertoire utilisateur /vagrant.
1
2
3
4
5
6
7
8
9
#!/bin/bash
for service in /etc/init.d/hadoop-hdfs-*
do
sudo $service start
done
for service in /etc/init.d/hadoop-yarn-*
do
sudo $service start
done
1
2
3
4
5
6
7
8
9
#!/bin/bash
for service in /etc/init.d/hadoop-yarn-*
do
sudo $service stop
done
for service in /etc/init.d/hadoop-hdfs-*
do
sudo $service stop
done
Changer finalement la permission sur les deux fichiers pour autoriser l’exécution.
1
chmod +x hadoop-*
Consulter les interfaces utilisateurs d’administrations
La distribution Hadoop par Apache fournit des interfaces utilisateurs pour l’administration. Ceux-ci sont accessibles via des applications Web.
La première concerne l’état du cluster et est accessible via l’adressse http://localhost:8088. Il vous sera possible d’avoir une vue globale sur les nœuds du cluster et sur les jobs en cours d’exécution. Une capture d’écran est donnée ci-dessous :
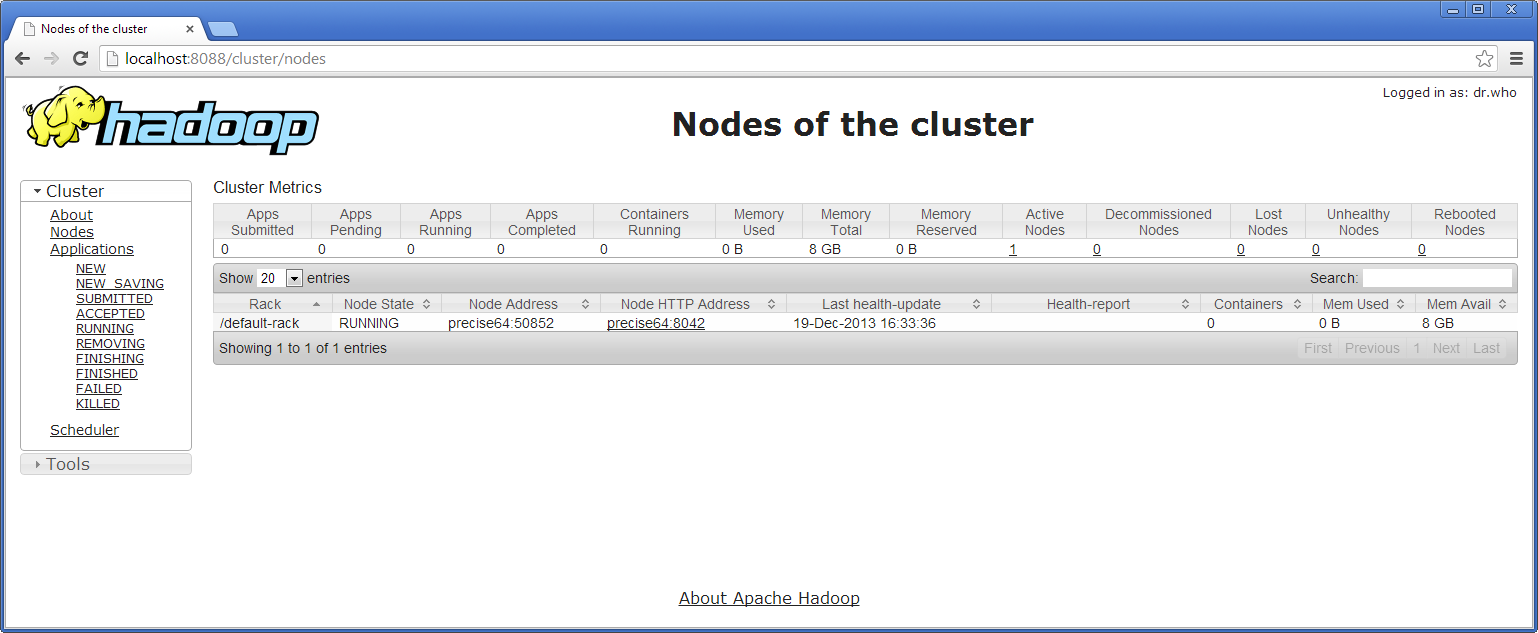
La deuxième interface utilisateur concerne l’accès aux données contenues dans le nœud NameNode et est accessible via l’adresse http://localhost:50070. Elle permet d’obtenir des informations sur la capacité totale et connaître l’état de disponibilité des nœuds. Elle permet également d’avoir des informations sur les fichiers et de naviguer dans le HDFS du cluster.
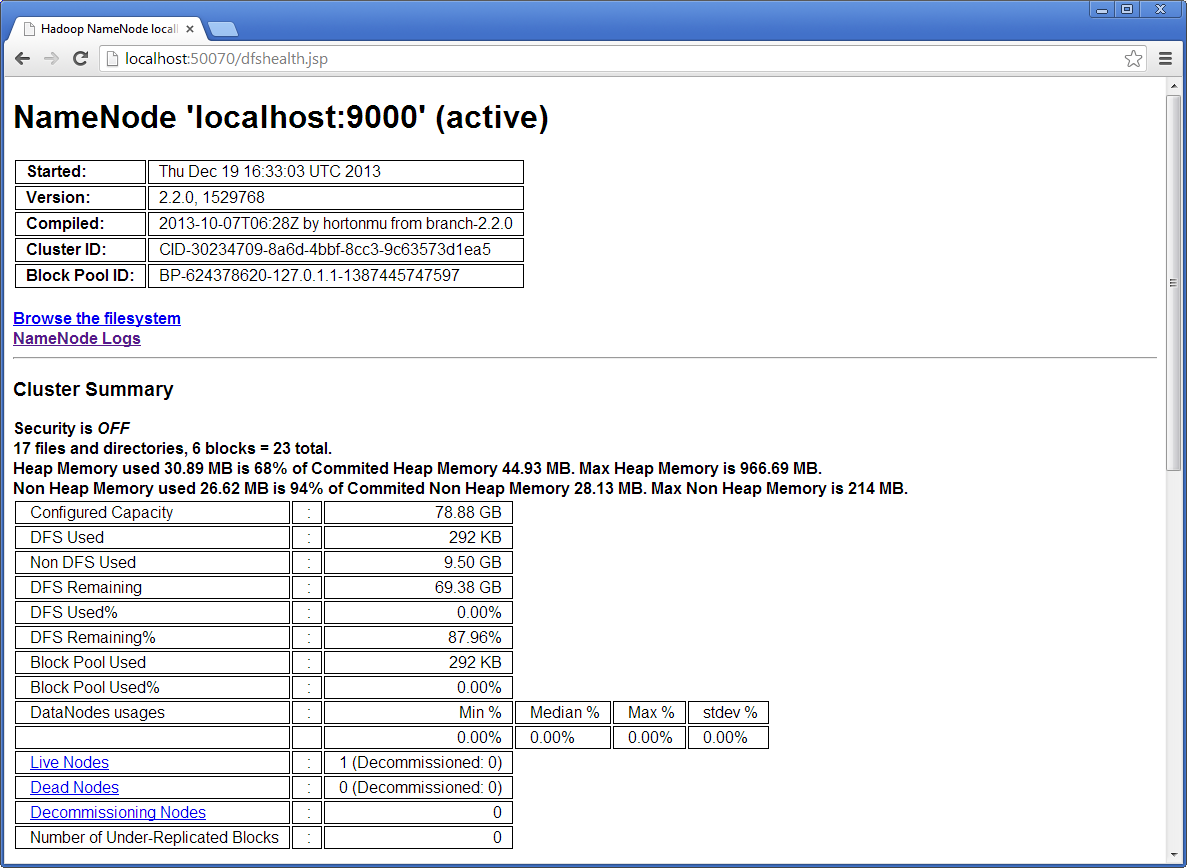
La troisième interface utilisateur concerne l’historique des jobs MapReduce et est accessible via l’adresse http://localhost:19888/jobhistory. Pour chaque job MapReduce exécuté, vous pourrez obtenir des métriques sur le temps moyen de la tâche map et reduce, obtenir le nombre de map, accéder aux logs de chaque tâche map exécutée, connaître pour chaque map le DataNode qui l’a éxécuté…
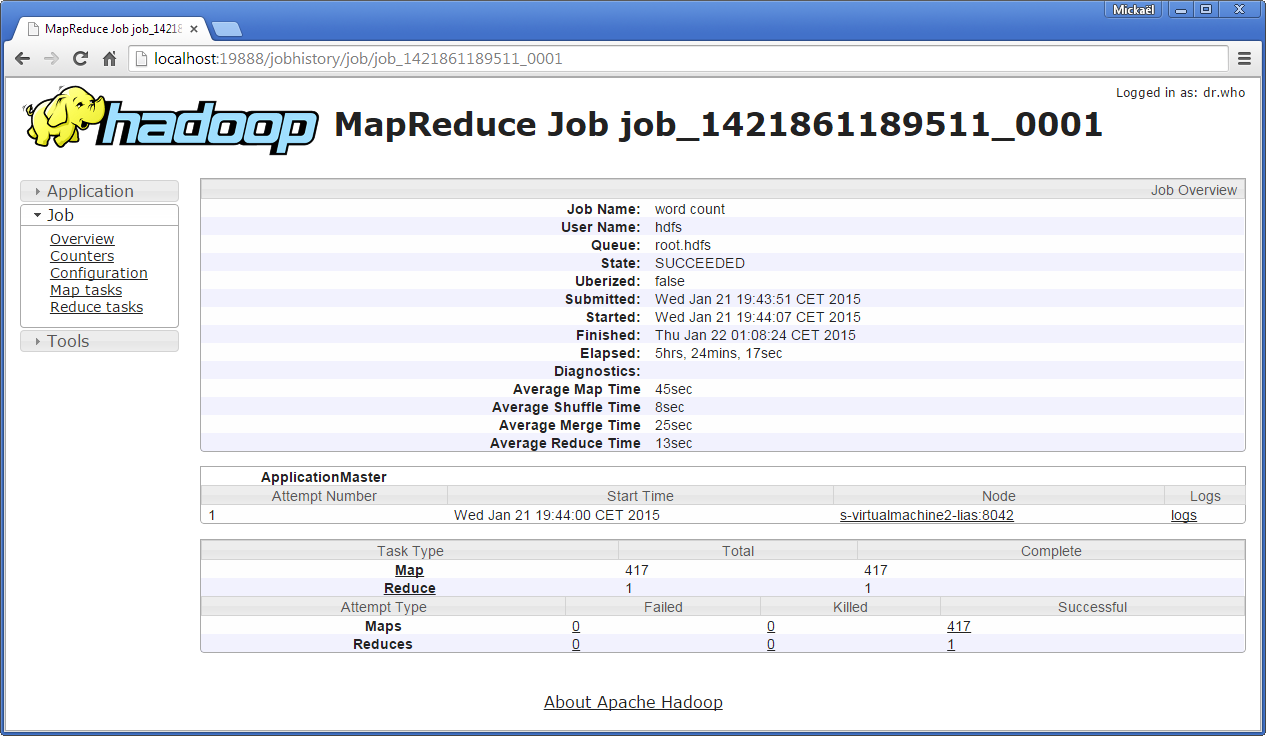
Nous utiliserons plus tard une application Web plus élaborée appelée Hue.
Manipulation du contenu HDFS
Il existe différentes façons d’interagir avec un système de fichiers HDFS telles que des API Java, des protocoles réseaux classiques (HTTP, FTP, WebHDFS, HttpFS…), des protocoles propriétaires (Amazon S3) ou tout simplement via la ligne de commandes. C’est ce dernier moyen d’interaction que nous allons détailler dans la suite de cette section.
HDFS s’appuie sur la spécification POSIX pour son système de fichiers. Il permet entre autres de pouvoir manipuler des fichiers et de disposer de droits sur ces fichiers. Notons qu’HDFS n’implémente pas totalement la spécification POSIX, ce qui a l’avantage d’améliorer les performances de débit des données.
Toutes les commandes supportées par HDFS sont disponibles via la commande suivante.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
$ hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|jobtracker:port> specify a job tracker
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
Comme vous pouvez le constatez il s’agit des commandes de bases qu’un utilisateur d’un système POSIX, Linux par exemple, aurait l’habitude de manipuler. Nous dénoterons toutefois deux principales différences.
- La première différence concerne l’appel à une commande HDFS qui doit se faire comme une sous-commande de la commande Hadoop. Cela peut vite devenir contraignant. De même, vous ne pourrez pas exploiter l’aide à la complétion sur les fichiers HDFS, il faudra saisir entièrement les noms de fichiers.
- La seconde différence concerne l’absence de répertoire courant. Il n’y a donc pas de possibilité d’utiliser la commande
cdpuisqu’elle n’existe pas. Par conséquent tous les chemins sont absolus ou relatifs par rapport au répertoire de l’utilisateur en cours (dans notre cas il s’agira de/user/hdfset/user/hduser). Pour le chemin absolu, deux écritures sont autorisées : une écriture via une URL, par exemple,hdfs://localhost:9000/monfichier/premierfichier.txtet une écriture via une URI, par exemple,/monfichier/premierfichier.txt. La localisation du namenodehdfs://localhost:9000est définie par la valeur de la propriétéfs.defaultFS(paramètre présent dans le fichiercore-site.xml). À noter que si un chemin absolu avec une URI est utilisé, il sera complété par la localisation du nœud namenode.
Concernant l’usage du chemin relatif dans le système de fichier HDFS, j’ai constaté que sur la version Cloudera, il était nécessaire d’initialiser soi-même le répertoire /user/[USER]. Nous ferons cette initialisation quand nous étudierons la mise en place des droits.
Intéressons-nous à expérimenter par des exemples l’usage de quelques commandes de base, à savoir l’affichage d’un répertoire, la copie de fichiers depuis ou vers HDFS, la suppression de fichiers et la modification des droits sur un répertoire.
Lecture du contenu d’un répertoire
La lecture d’un fichier se fera par la sous commande -ls. L’exemple ci-dessous liste l’ensemble des fichiers du répertoire utilisateur hdfs.
1
2
3
4
$ sudo -u hdfs hadoop fs -ls
Found 2 items
-rw-r--r-- 1 hdfs hadoop 594933 2014-01-14 10:47 pg1661.txt
-rw-r--r-- 1 hdfs hadoop 1423803 2014-01-14 10:48 pg5000.txt
Les informations retournées sont très similaires à ce qu’on obtient avec la commande Linux ls -l, à part une différence notable qui vient de la seconde colonne donnant le facteur de réplication du fichier considéré. Dans notre cas, celui-ci vaut 1 puisque nous avons configuré un cluster avec un nœud unique.
Nous donnons ci-dessous un exemple qui liste le contenu du répertoire racine en utilisant un chemin absolu via une URI /.
1
2
3
$ sudo -u hdfs hadoop fs -ls /
Found 1 items
drwxr-xr-x - hdfs hadoop 0 2013-12-19 15:55 /user
Ci-dessous nous obtenons le même résultat en utilisant cette fois un chemin absolu via une URL hdfs://localhost:9000/.
1
2
3
$ sudo -u hdfs hadoop fs -ls hdfs://localhost:9000/
Found 1 items
drwxr-xr-x - hdfs hadoop 0 2013-12-19 15:55 hdfs://localhost:9000/user
Copie de fichiers
La copie de fichiers est similaire à ce que nous pouvons réaliser depuis un système de fichiers distant comme par exemple FTP. Ainsi, la copie de fichiers vers le système de fichiers HDFS depuis le système local, se fait via la commande -put ou son alias -copyFromLocal. La copie de fichiers vers le système local ou vers le système de fichiers HDFS se fait via la commande -get ou son alias -copyToLocal. À noter que les commandes -moveFromLocal et -moveToLocal copieront les fichiers depuis ou vers le système de fichiers HDFS et supprimeront les fichiers sources.
Ci-dessous nous donnons un exemple permettant de copier un fichier depuis le système de fichiers local vers le système de fichiers HDFS.
1
2
3
4
5
6
$ sudo -u hdfs hadoop fs -put /vagrant/files/pg19699.txt
$ hadoop fs -ls
Found 3 items
-rw-r--r-- 1 hdfs hadoop 594933 2014-01-14 11:30 pg1661.txt
-rw-r--r-- 1 hdfs hadoop 1945886 2014-01-14 11:32 pg19699.txt
-rw-r--r-- 1 hdfs hadoop 1423803 2014-01-14 10:48 pg5000.txt
Enfin, nous donnons à la suite un exemple permettant de copier un fichier depuis le système de fichiers HDFS vers le système de fichiers local.
1
2
3
4
5
6
7
$ sudo -u hdfs hadoop fs -get pg19699.txt /vagrant/files/pg19699-copy.txt
$ ls -l /vagrant/files/
total 5773
-rwxrwxrwx 1 vagrant vagrant 594933 Jan 14 10:36 pg1661.txt
-rwxrwxrwx 1 vagrant vagrant 1945886 Jan 14 11:35 pg19699-copy.txt
-rwxrwxrwx 1 vagrant vagrant 1945886 Jan 14 11:31 pg19699.txt
-rwxrwxrwx 1 vagrant vagrant 1423803 Jan 14 10:25 pg5000.txt
Suppression de fichiers
Dans l’exemple qui suit, nous montrons comment supprimer un fichier depuis le système de fichiers HDFS avec la commande -rm.
1
2
3
$ sudo -u hdfs hadoop fs -rm pg19699.txt
14/01/14 11:48:35 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted pg19699.txt
Droits sur les ressources
Nous allons nous intéresser à créer un répertoire via -mkdir et donner un droit d’accès -chown à un utilisateur du système hôte. On va donc créer le répertoire /user/hduser et lui donner les droits pour l’utilisateur hduser et pour le groupe hadoop.
1
2
3
4
sudo -u hdfs hadoop fs -mkdir /user
sudo -u hdfs hadoop fs -mkdir /user/hduser
sudo -u hdfs hadoop fs -chown hduser /user/hduser
sudo -u hdfs hadoop fs -chown :hadoop /user/hduser
Pour s’assurer que les droits sont correctement mis, le contenu du répertoire /user est listé.
1
2
3
4
$ sudo -u hdfs hadoop fs -ls /user
Found 2 items
drwxr-xr-x - hdfs hadoop 0 2014-01-17 18:28 /user/hdfs
drwxr-xr-x - hduser hadoop 0 2014-01-17 18:28 /user/hduser
Vous pouvez maintenant vous connecter en hduser depuis le système hôte et ajouter des ressources au répertoire HDFS /user/hduser.
Exécution d’un exemple de job MapReduce
Puisque Hadoop est désormais opérationnel, nous allons exécuter deux jobs MapReduce fournis comme exemple, depuis la distribution Hadoop. Les exemples sont disponibles sous forme de Jar (hadoop-mapreduce-examples.jar) depuis le répertoire /usr/lib/hadoop-mapreduce.
Estimer la valeur pi
Ce premier job MapReduce permet d’estimer la valeur du nombre pi. Il ne requiert pas de fichiers depuis le système de fichiers HDFS.
1
sudo -u hduser hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 2 5
L’exécution prendra un certain temps (10 secondes) à s’exécuter sur l’unique nœud. La sortie générée ressemble à quelque chose comme cela :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
Number of Maps = 2
Samples per Map = 5
Wrote input for Map #0
Wrote input for Map #1
Starting Job
...
14/01/29 23:35:46 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
14/01/29 23:35:46 INFO mapreduce.Job: Running job: job_local1171327146_0001
14/01/29 23:35:47 INFO mapreduce.Job: Job job_local1171327146_0001 running in uber mode : false
14/01/29 23:35:48 INFO mapreduce.Job: map 0% reduce 0%
14/01/29 23:35:49 INFO mapreduce.Job: map 100% reduce 0%
14/01/29 23:35:51 INFO mapreduce.Job: map 100% reduce 100%
14/01/29 23:35:51 INFO mapreduce.Job: Job job_local1171327146_0001 completed successfully
14/01/29 23:35:51 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=812626
FILE: Number of bytes written=1408734
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=590
HDFS: Number of bytes written=923
HDFS: Number of read operations=33
HDFS: Number of large read operations=0
HDFS: Number of write operations=15
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=294
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=0
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=128
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=435634176
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 10.98 seconds
Estimated value of Pi is 3.60000000000000000000
Après l’exécution de ce job MapReduce, on peut constater que :
- L’estimation du nombre pi est très éloignée ;
- L’exécution du job MapReduce est lente. Bien sûr ces points peuvent être résolus si on augmente le nombre de Map à traiter (ici 2), le nombre d’échantillons par Map (ici 5) et surtout le nombre de nœuds, puisque c’est tout l’intérêt d’un cluster Hadoop.
Compter le nombre de mots
Ce job MapReduce, déjà présenté lors du premier tutoriel ‘Généralités sur HDFS et MapReduce’, permet de lire des fichiers textes et de compter les occurrences des mots. L’entrée du job sont des fichiers textes. Les fichiers sont accessibles depuis le système de fichiers HDFS.
Pour les jeux de données nous utiliserons trois livres en accès libres disponibles depuis le site http://www.gutenberg.org.
- Les notes de Leonardo Da Vinci par Leonardo Da Vinci.
- Les aventures de Sherlock Holmes par Arthur Conan Doyle.
- Les misérables par Victor Hugo.
Pour chaque livre, télécharger le texte brute.
- Les notes de Leonardo Da Vinci (1.4 Mo).
- Les aventures de Sherlock Holmes (581 ko).
- Les misérables (3.2 Mo).
Depuis le système de fichier HDFS, créer un répertoire /user/hduser/books puis copier à l’intérieur les trois fichiers de type texte.
1
2
3
4
sudo -u hduser hadoop fs -mkdir /user/hduser/books
sudo -u hduser hadoop fs -put /vagrant/files/books/pg5000.txt /user/hduser/books
sudo -u hduser hadoop fs -put /vagrant/files/books/pg1661.txt /user/hduser/books
sudo -u hduser hadoop fs -put /vagrant/files/books/pg135.txt /user/hduser/books
Exécuter la commande suivante pour démarrer le job.
1
sudo -u hduser hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount books output
L’exécution prendra un court instant, le message de sortie ressemble à quelque chose comme cela :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
14/01/30 23:45:30 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
14/01/30 23:45:30 INFO mapreduce.Job: Running job: job_local179811_0001
14/01/30 23:45:31 INFO mapreduce.Job: Job job_local179811_0001 running in uber mode : false
14/01/30 23:45:31 INFO mapreduce.Job: map 0% reduce 0%
14/01/30 23:45:41 INFO mapreduce.Job: map 100% reduce 0%
14/01/30 23:45:44 INFO mapreduce.Job: map 33% reduce 0%
14/01/30 23:45:45 INFO mapreduce.Job: map 100% reduce 0%
14/01/30 23:45:52 INFO mapreduce.Job: map 100% reduce 100%
14/01/30 23:45:52 INFO mapreduce.Job: Job job_local179811_0001 completed successfully
14/01/30 23:45:53 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=2575311
FILE: Number of bytes written=6916065
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=18751879
HDFS: Number of bytes written=886494
HDFS: Number of read operations=37
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Map-Reduce Framework
Map input records=113284
Map output records=927416
Map output bytes=8898202
Map output materialized bytes=1490616
Input split bytes=344
Combine input records=927416
Combine output records=101838
Reduce input groups=80711
Reduce shuffle bytes=0
Reduce input records=101838
Reduce output records=80711
Spilled Records=203676
Shuffled Maps =0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=1141
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=778051584
File Input Format Counters
Bytes Read=5341387
File Output Format Counters
Bytes Written=886494
Après un petit instant, le résultat de l’analyse est disponible dans le répertoire /user/hduser/output/part-r-00000. Pour visualiser le contenu vous pouvez utiliser la commande cat.
1
sudo -u hduser hadoop fs -cat /user/hduser/output/part-r-00000
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
"27
"'A 1
"'About 1
"'Absolute 1
"'Ah!' 2
"'Ah, 2
"'Ample.' 1
"'And 10
"'Arthur!' 1
"'As 1
"'At 1
"'Because 1
"'Breckinridge, 1
"'But 1
"'But, 1
"'But,' 1
"'Certainly 2
"'Certainly,' 1
"'Come! 1
"'Come, 1
"'DEAR 1
"'Dear 2
"'Dearest 1
"'Death,' 1
"'December 1
"'Do 3
"'Don't 1
"'Entirely.' 1
"'Flock'; 1
"'For 1
...
Comme vous pouvez le constater, la ponctuation du texte pollue les résultats. Nous procéderons à une modification du code du job MapReduce dans le prochain article.
Administrer avec Hue
Hue est une application Web open source qui propose des interfaces utilisateurs nettement plus élaborées que celles fournies de base par Apache Hadoop. L’idée proposée par Hue est de simplifier l’utilisation d’Hadoop et de ses sous-projets. Il est donc possible depuis un navigateur Web de manipuler entre autres, le système de fichiers HDFS, de visualiser et d’exécuter un job MapReduce ou de saisir des requêtes pour Apache Hive…
Installer et configurer Hue
L’installation de Hue se fait assez facilement depuis la distribution fournie par Cloudera. Pensez, avant de commencer l’installation, à mettre à jour le cache des paquets sur votre machine.
1
sudo apt-get update
Exécuter la commande suivante pour installer Hue.
1
sudo apt-get install hue
Installer également le projet Oozie qui est un ordonnanceur pour les jobs MapReduce.
1
2
sudo apt-get install oozie
sudo apt-get install oozie-client
Vous ne devriez pas avoir de surprise lors de l’installation de ces packages.
Concernant la configuration de Hue, nous avions pris de l’avance en section Fichiers de configuration Hadoop, en configurant les fichiers core-site.xml et hdfs-site.xml. Hue a besoin du protocole WebHDFS pour communiquer avec le système de fichiers HDFS.
Accueil Hue
L’interface de connexion permet de s’identifier à Hue. Il vous sera demandé lors de la première connexion de créer un utilisateur. Créez un utilisateur hduser et le mot de passe hduser.

Une fois connecté avec l’utilisateur hduser, vous arriverez sur l’écran d’accueil de Hue. Celui-ci présente sur le bandeau du haut, un menu qui vous permettra d’accéder aux différentes applications liées aux projets Hadoop. Par exemple pour Query Editors, vous pourrez accéder à un éditeur de requêtes pour Apache Hive. De même, pour Data Browsers, vous pourrez accéder à un visualiseur de données pour HBase.
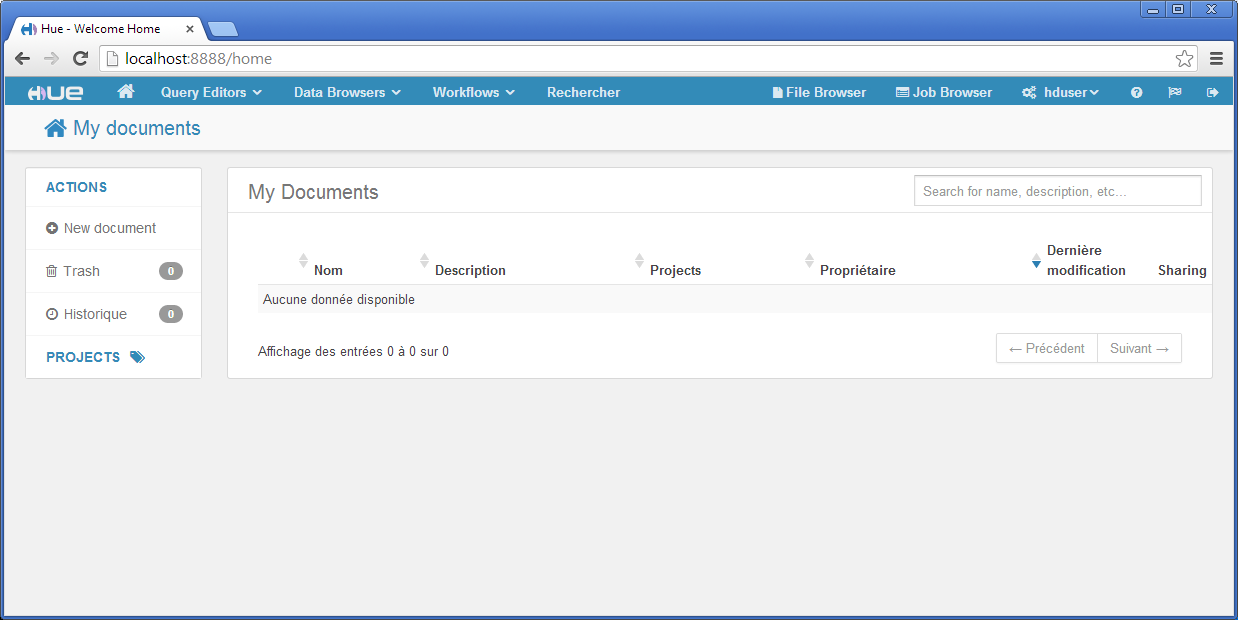
Dans la suite, nous allons nous focaliser sur les interfaces utilisateurs permettant de manipuler le système de fichiers HDFS et de gérer les jobs MapReduce.
File Browser
Cet outil permet de profiter d’une interface graphique pour manipuler le contenu HDFS. Sur la figure ci-dessous nous montrons le contenu du répertoire /user/hduser/books contenant les trois livres libres de droits.
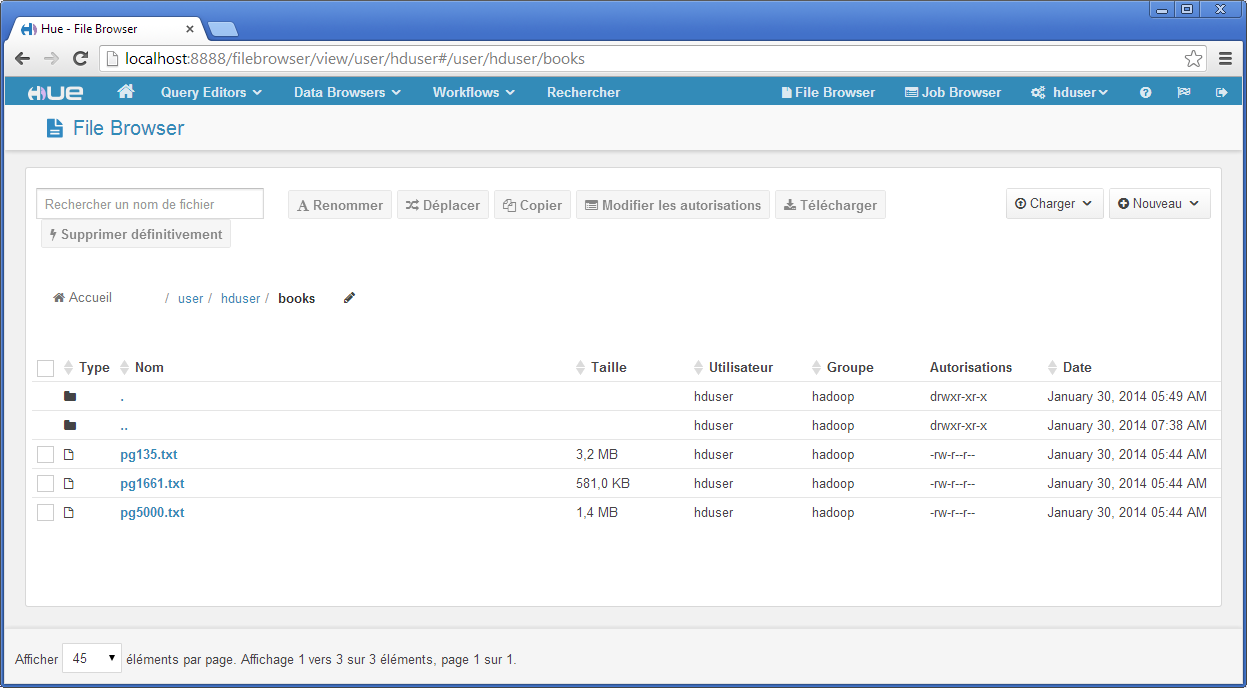
Les principales fonctionnalités d’un gestionnaire de fichiers sont disponibles. Toutefois, cette interface est à réserver pour la manipulation de quelques fichiers. Une approche par FTP ou par shell (fuse) sera alors préférée quand il y aura besoin de manipuler un nombre important de fichiers.
Job Browser
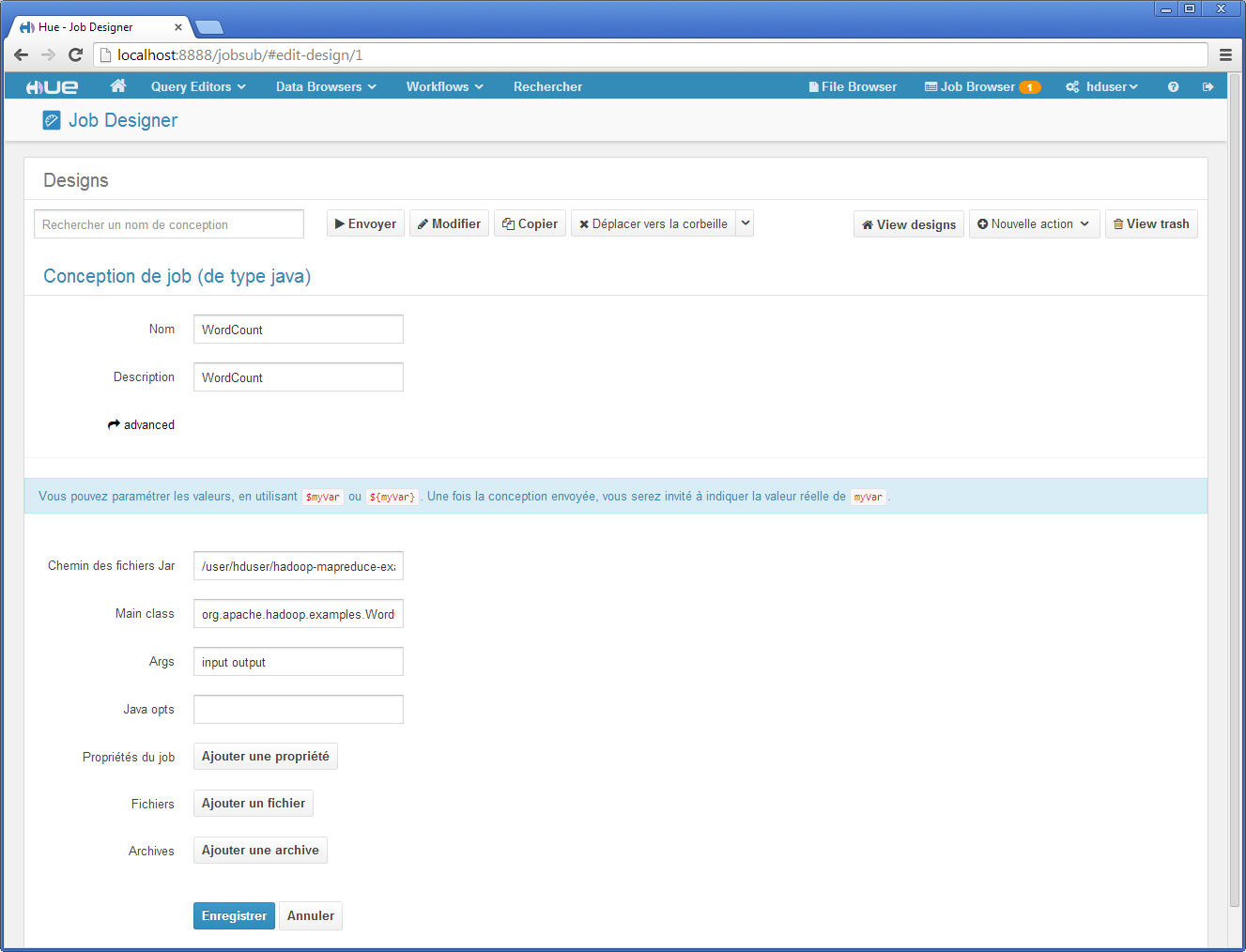
Hue facilite la création, le contrôle et la planification de l’ordre d’exécution de jobs MapReduce. Hue est associée au projet Oozie pour la gestion de la planification de jobs MapReduce. Nous montrons ci-dessous quelques interfaces fournies par Hue pour définir, planifier et exécuter le job MapReduce de compteur d’occurrences de mots.
La capture d’écran ci-dessous présente la création d’un job MapReduce développé en Java. Sont données les informations concernant le Jar (localisé dans le HDFS de l’utilisateur), la class Main (org.apache.hadoop.examples.WordCount) et deux arguments input output désignant respectivement le répertoire contenant les livres et où placer le résultat du job.
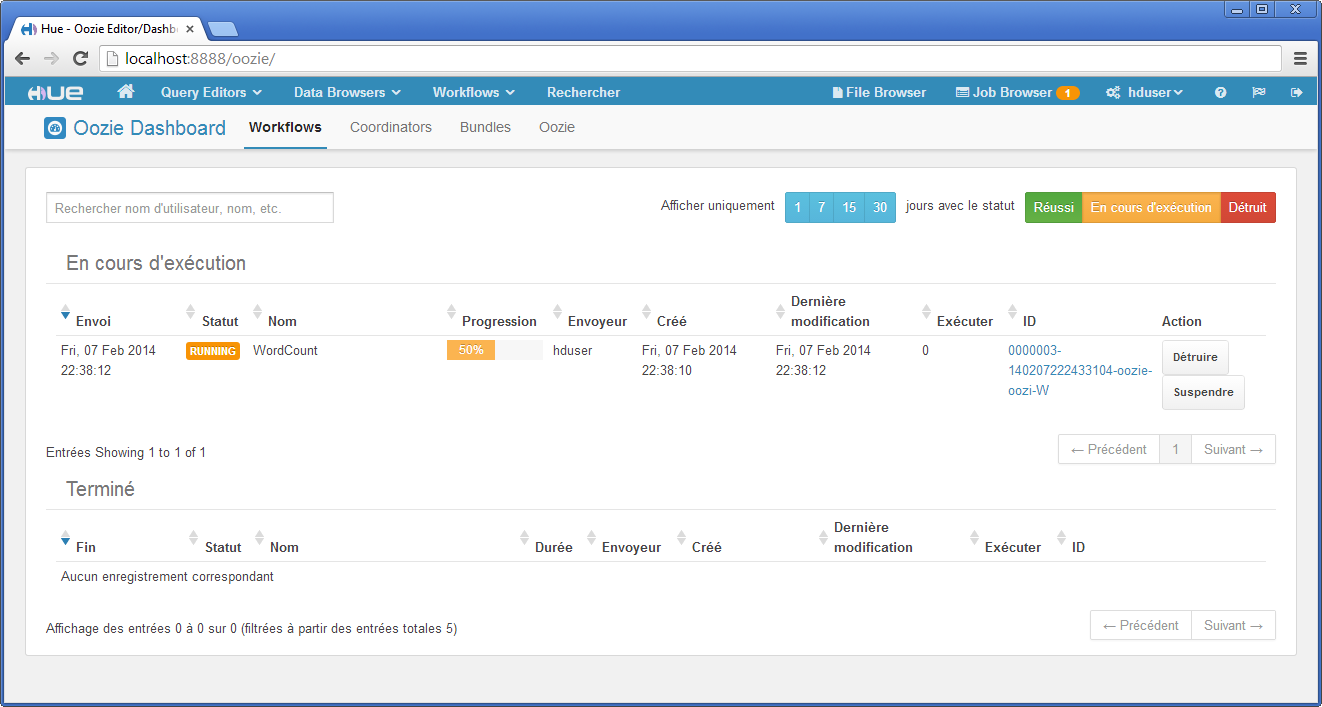
La capture d’écran ci-dessous montre l’interface de l’ordonnanceur des jobs MapReduce.
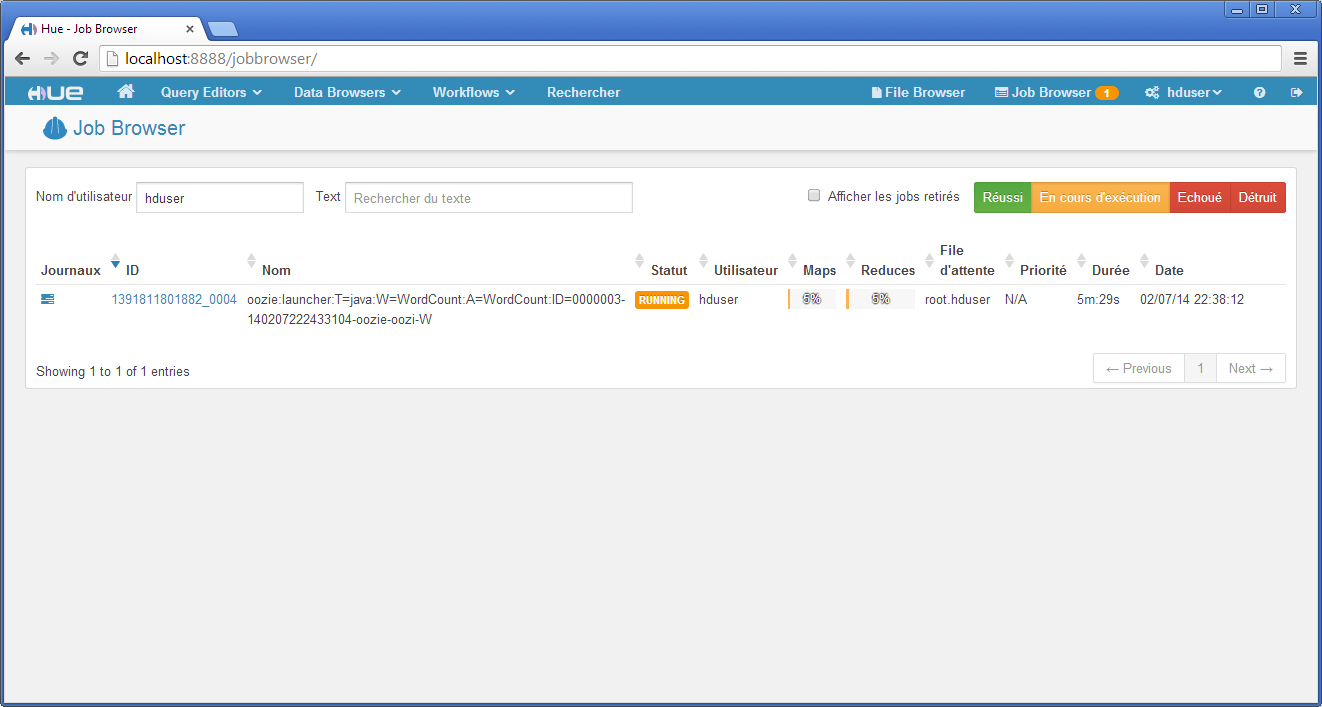
Enfin, la capture d’écran qui suit montre la liste des jobs en cours d’exécution. Toutes les entrées sont cliquables afin d’obtenir des informations détaillées sur l’état du job.
Conclusion et perspectives
Dans cet article nous nous sommes intéressés à présenter les généralités d’Hadoop (HDFS et MapReduce) et à fournir une installation Hadoop de type simple nœud. Nous tenons à rappeler que l’objectif d’un cluster simple nœud a pour vocation d’être pédagogique (comprendre les fichiers de configuration, les outils de base…) et de disposer d’un environnement de développement pour tester ses développements de jobs MapReduce.
Ainsi, dans le prochain tutoriel de cette série, nous montrerons comment développer un job MapReduce sous Eclipse et comment le déployer sur le cluster simple nœud. Nous montrerons à cet effet comment déboguer son job MapReduce à distance.
Je tiens à remercier jacques_jean pour sa relecture orthographique attentive de cet article.
Bonus
Nous expliquons dans cette section comment mettre en place cette virtualisation avec VirtualBox et Vagrant et comment automatiser l’installation des outils avec Puppets.
Automatiser l’installation et l’exécution d’un cluster Hadoop Cloudera simple nœud avec Vagrant et Puppets
Cette section présente rapidement le script Puppet qui automatise l’installation présentée dans les précédentes sections. Le projet complet est disponible sur mon GitHub : https://github.com/mickaelbaron/vagrant-cloudera5-precise64.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
class hadoopmonocluster::prepare {
exec { "apt-update":
command => "/usr/bin/apt-get -y update",
timeout => 3600;
}
package {
["openjdk-7-jdk", "curl"]:
ensure => installed;
}
exec {
"addgrouphadoop":
command => "/usr/sbin/addgroup hadoop",
timeout => 0;
"addhdsuer":
command => "/usr/sbin/adduser --ingroup hadoop --disabled-password --gecos '' hduser",
timeout => 0,
require => Exec['addgrouphadoop'];
"changepassword":
command => "/bin/echo -e 'hduser\nhduser' | /usr/bin/passwd hduser",
timeout => 0,
require => Exec['addhdsuer'];
"wgetcdh5":
cwd => "/vagrant/modules/files",
command => "/usr/bin/wget http://archive.cloudera.com/cdh5/one-click-install/precise/amd64/cdh5-repository_1.0_all.deb",
timeout => 0,
creates => "/vagrant/modules/files/cdh5-repository_1.0_all.deb",
require => Exec['addhdsuer'];
"dpkgcdh5":
command => "/usr/bin/dpkg -i cdh5-repository_1.0_all.deb",
cwd => "/vagrant/modules/files",
timeout => 0,
require => Exec['wgetcdh5'];
"curlcdh5":
command => "/usr/bin/curl -s http://archive.cloudera.com/cdh5/ubuntu/precise/amd64/cdh/archive.key | sudo apt-key add -",
cwd => "/vagrant/modules/files",
timeout => 0,
require => Exec['dpkgcdh5'];
}
}
class hadoopmonocluster::install {
exec { "apt-update-cloudera":
command => "/usr/bin/apt-get -y update",
timeout => 3600;
}
package {
["hadoop-yarn-resourcemanager", "hadoop-hdfs-namenode", "hadoop-yarn-nodemanager", "hadoop-hdfs-datanode", "hadoop-mapreduce", "hadoop-mapreduce-historyserver"]:
ensure => installed,
require => Exec['apt-update-cloudera'];
}
service {
["hadoop-hdfs-datanode", "hadoop-hdfs-namenode", "hadoop-yarn-nodemanager", "hadoop-yarn-resourcemanager"]:
ensure=> "stopped";
}
}
class hadoopmonocluster::postinstall {
file {
"/etc/hadoop/conf/core-site.xml":
ensure => present,
source => "puppet:///modules/hadoopmonocluster/core-site.xml";
"/etc/hadoop/conf/hdfs-site.xml":
ensure => present,
source => "puppet:///modules/hadoopmonocluster/hdfs-site.xml";
"/etc/hadoop/conf/mapred-site.xml":
ensure => present,
source => "puppet:///modules/hadoopmonocluster/mapred-site.xml";
"/home/vagrant/hadoop-start":
ensure => present,
source => "puppet:///modules/hadoopmonocluster/hadoop-start",
mode => 777;
"/home/vagrant/hadoop-stop":
ensure => present,
source => "puppet:///modules/hadoopmonocluster/hadoop-stop",
mode => 777;
}
}
Trois classes sont définies. La première hadoopmonocluster::prepare, à la ligne 1, s’intéresse à la préparation de l’installation. La JDK 7 est installée, puis un groupe et un utilisateur sont créés. La deuxième hadoopmonocluster::install à la ligne 43 réalise l’installation des packages Cloudera. Finalement la troisième hadoopmonocluster::postinstall copie les fichiers de configuration déjà modifiés.
Sur la configuration Vagrant ci-dessous, vous remarquerez à partir de la ligne 4, la redirection des ports qui permet d’accéder aux interfaces Web depuis la machine hôte.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Vagrant.configure("2") do |config|
config.vm.box = "precise64"
config.vm.hostname = "vagrant-cloudera5-ubuntu64"
config.vm.network :forwarded_port, host: 8088, guest: 8088
config.vm.network :forwarded_port, host: 50070, guest: 50070
config.vm.network :forwarded_port, host: 10020, guest: 10020
config.vm.network :forwarded_port, host: 19888, guest: 19888
config.vm.provider :virtualbox do |vb|
vb.customize ["modifyvm", :id,
"--name", "vagrant-cloudera5-ubuntu64-build",
"--memory", "4096",
"--natdnshostresolver1", "on"]
end
config.vm.provision :puppet do |puppet|
puppet.manifests_path = "manifests"
puppet.module_path = "modules"
puppet.manifest_file = "base.pp"
puppet.options = "--verbose"
end
end
Monter un disque HDFS avec Fuse et Cloudera
Cette section décrit comment monter HDFS comme un système de fichiers standard par l’intermédiaire de la commande mount. Une fois HDFS monté, vous pourrez alors utiliser les commandes standards fournies par le système de fichiers Linux. Ceci offre l’avantage de simplifier la manipulation d’HDFS, car il n’y aura plus besoin d’utiliser les sous-commandes Hadoop.
Pour monter HDFS nous allons installer Fuse. La configuration de Fuse pour Hadoop se fait facilement avec la distribution de Cloudera. La même chose via la distribution Apache Hadoop n’est pas si facile. N’étant pas un expert de Fuse, j’ai rapidement abandonné au profit de la version Cloudera.
Pour l’installation de Fuse pour Hadoop, il vous suffit d’installer le package fourni par Cloudera.
1
sudo apt-get install hadoop-hdfs-fuse
Nous allons créer un répertoire hdfs depuis le répertoire utilisateur hduser qui servira de répertoire de montage. Les opérations se feront depuis un utilisateur sudoers.
1
2
cd /home/hduser
mkdir hdfs
La dernière étape consiste à réaliser le montage, à proprement parler.
1
2
3
$ sudo hadoop-fuse-dfs dfs://localhost:9000 /home/hduser/hdfs/
INFO /var/lib/jenkins/workspace/generic-package-ubuntu64-12-04/CDH5beta1-Packaging-Hadoop-2013-10-27_17-04-57/hadoop-2.2.0+cdh5.0.0+353-0.cdh5b1.p0.79~precise/hadoop-hdfs-project/hadoop-hdfs/src/main/
native/fuse-dfs/fuse_options.c:164 Adding FUSE arg /home/hduser/hdfs/
Pour tester, connectez-vous via l’utilisateur hduser et déplacez-vous dans le répertoire /home/hduser/hdfs.
Installer la distribution Hadoop de la fondation Apache
Nous montrerons dans cette section l’installation de la distribution Hadoop fournie par Apache. Je ciblerai la version Hadoop 2.3.0. Téléchargez le fichier et placez-le dans le répertoire utilisateur hduser.
Pour l’installation, j’utiliserai par convention le répertoire /usr/local. Décompressez l’archive d’Hadoop dans le répertoire /usr/local via la commande suivante :
1
sudo tar xzf /home/hduser/hadoop-2.3.0.tar.gz -C /usr/local/
Cela permet de créer un répertoire /usr/local/hadoop-2.3.0. Afin de faciliter l’utilisation du chemin, nous utiliserons un lien symbolique de /usr/local/hadoop-2.3.0 vers /usr/local/hadoop.
1
ln -s /usr/local/hadoop-2.3.0 hadoop
Enfin, nous changeons l’attribution des droits pour l’utilisateur hduser et le groupe hadoop.
1
$ sudo chown -R hduser:hadoop hadoop hadoop-2.3.0
Fichiers de configuration utilisateur hduser
Seul le fichier de configuration utilisateur .bashrc a besoin d’être modifié afin qu’il propage les nouvelles valeurs des variables d’environnement. Ouvrir le fichier /home/hduser/.bashrc et ajouter à la fin du fichier les lignes suivantes :
1
2
3
4
5
6
...
# Hadoop Environment Variables
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
Assurez-vous qu’à l’ouverture d’une session hduser les variables d’environnement sont correctement prises en compte.
Fichiers de configuration Hadoop
Tous les fichiers de configuration d’Hadoop sont disponibles dans le répertoire %HADOOP_HOME/etc/hadoop.
hadoop-env.sh
Le fichier %HADOOP_HOME/etc/hadoop/hadoop-env.sh contient des variables d’environnement utilisées par Hadoop. Seule la variable JAVA_HOME est à modifier. À noter que si vous commenter cette variable, la valeur définie dans le fichier .bashrc sera prise en compte.
1
2
3
4
5
6
7
8
9
...
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
...
core-site.xml
Dans le fichier %HADOOP_HOME/etc/hadoop/core-site.xml, modifier le contenu afin d’obtenir le résultat ci-dessous :
1
2
3
4
5
6
7
8
9
10
11
12
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hduser/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<description>The name of the default file system.</description>
</property>
</configuration>
La propriété hadoop.tmp.dir précise le répertoire contenant tous les fichiers de travail pour Hadoop. Par défaut les fichiers HDFS seront stockés dans un sous-répertoire défini par hadoop.tmp.dir. La propriété fs.defaultFS permet de spécifier quant à elle le nom du système de fichier.
hdfs-site.xml
Le fichier %HADOOP_HOME/etc/hadoop/hdfs-site.xml contient les paramètres spécifiques au système de fichiers HDFS.
1
2
3
4
5
6
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Le paramètre dfs.replication permet de préciser le nombre de réplication d’un block.
Initialisation du système de fichier HDFS
Avant de démarrer le serveur Hadoop, vous devez formater le système de fichiers HDFS. Dans le cas de cette installation d’un cluster simple nœud, seul le système de fichiers HDFS de votre machine locale sera formaté. Pour formater, exécuter la commande suivante :
1
hdfs namenode -format
Démarrage et arrêt d’un serveur Hadoop
Pour démarrer Hadoop, vous aurez besoin de démarrer le système de fichiers HDFS et le serveur MapReduce dans le cas où vous souhaitez utiliser des jobs MapReduce.
La commande suivante démarre le système de fichiers HDFS.
1
start-dfs.sh
À la suite de cette exécution vous obtiendrez un résultat équivalent.
1
2
3
4
5
6
7
8
$ start-dfs.sh
13/12/19 10:35:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop-2.3.0/logs/hadoop-hduser-namenode-precise64.out
localhost: starting datanode, logging to /usr/local/hadoop-2.3.0/logs/hadoop-hduser-datanode-precise64.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.3.0/logs/hadoop-hduser-secondarynamenode-precise64.out
13/12/19 10:35:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Vous noterez qu’à la ligne 1 et 5, il y a un avertissement sur l’impossibilité de charger des bibliothèques natives. Ces dernières sont utilisées pour améliorer l’efficacité de certains traitements et pour pallier certains manques des implémentations Java. L’erreur est dû au fait que les bibliothèques incluses dans la distribution binaire d’Hadoop sont des bibliothèques pour des systèmes 32 bits. Les versions 64 bits ne sont pas fournies. Pour résoudre ce problème qui n’est pas essentiel pour utiliser Hadoop, je vous invite à consulter à la fin dans cette section : comment compiler Hadoop et générer les nouvelles bibliothèques natives.
Il faut ensuite démarrer le serveur MapReduce en exécutant la commande suivante :
1
2
3
4
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.3.0/logs/yarn-hduser-resourcemanager-precise64.out
localhost: starting nodemanager, logging to /usr/local/hadoop-2.3.0/logs/yarn-hduser-nodemanager-precise64.out
Pour s’assurer que tout fonctionne, utiliser l’outil jps pour lister les processus Java en cours d’exécution :
1
2
3
4
5
6
7
$ jps -lm
13958 org.apache.hadoop.yarn.server.nodemanager.NodeManager
13855 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
13543 org.apache.hadoop.hdfs.server.datanode.DataNode
13702 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
13415 org.apache.hadoop.hdfs.server.namenode.NameNode
14332 sun.tools.jps.Jps -lm
Depuis la version 2.3.x d’Hadoop, ResourceManager remplace JobTracker.
Enfin, pour arrêter un serveur Hadoop, vous devrez utiliser la commande suivante pour interrompre le serveur de fichiers HDFS :
1
2
3
4
5
6
$ stop-dfs.sh
Stopping namenodes on [localhost]
localhost: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
et la commande suivante pour interrompre le serveur MapReduce :
1
2
3
4
5
$ stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
localhost: stopping nodemanager
no proxyserver to stop
Résoudre le problème : unable to load native-hadoop library for your platform
Si vous installez la version Hadoop fournie par Apache, il se peut que vous ayez à résoudre le problème de util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable. Pour cela il faut fournir à Hadoop des versions 64 bits des bibliothèques natives contenues dans le répertoire %HADOOP_HOME/lib/native. Une des solutions que je vous propose est de compiler depuis un système 64 bits les sources d’Hadoop.
Prérequis logiciels et installation
La liste des logiciels nécessaires à la compilation est la suivante :
- Maven : outils de build pour Java ;
- libssl-dev : bibliothèque de développement SSL ;
- cmake : outils de build ;
- g++ : compilateur C++ ;
- Protocol Buffers : format de sérialisation.
Pour l’installation des quatre premiers, nous ferons appel aux packages Debian. Exécuter la commande suivante via un utilisateur sudo (dans mon cas vagrant est un utilisateur sudo) :
1
sudo apt-get install maven libssl-dev cmake g++
Concernant l’installation de Protocol Buffers, la compilation d’Hadoop requiert la version 2.5. Comme les dépôts Debian ne proposent que la version 2.4, nous allons devoir compiler en local Protocol Buffers et insérer son répertoire bin dans PATH. Veuillez suivre les indications suivantes à partir de l’utilisateur vagrant :
1
2
3
4
5
6
7
cd
wget https://protobuf.googlecode.com/files/protobuf-2.5.0.tar.gz
tar zxvf protobuf-2.5.0.tar.gz
cd protobuf-2.5.0/
./configure --prefix=`pwd`/inst
make
make install
Après la compilation et l’installation, le résultat obtenu est disponible dans le répertoire protobyf-2.5.0/inst.
Il faut maintenant rendre accessible le binaire de Protocol Buffers via l’utilisation de la variable PATH. Pour cela exécuter la commande suivante :
1
export PATH=`pwd`/inst/bin:$PATH
Pour s’assurer que Protocol Buffers, exécuter la commande suivante :
1
2
$ proto --version
libprotoc 2.5.0
Télécharger et compiler les sources Hadoop
Les sources Hadoop sont disponibles au même emplacement que les binaires. Exécuter la commande suivante depuis le répertoire utilisateur de vagrant :
1
2
3
4
5
6
cd
wget http://wwwftp.ciril.fr/pub/apache/hadoop/common/hadoop-2.3.0/hadoop-2.3.0-src.tar.gz
tar zxvf hadoop-2.3.0-src.tar.gz
cd hadoop-2.3.0-src
wget https://issues.apache.org/jira/secure/attachment/12614482/HADOOP-10110.patch
patch -p0 < HADOOP-10110.patch
Finalement les sources sont disponibles pour être compilées, exécuter la commande suivante en prenant soin de désactiver les tests :
1
$ mvn package -Pdist,native -DskipTests -Dtar
Déposer les nouvelles versions de bibliothèques natives
Toujours depuis l’utilisateur vagrant, copier dans le répertoire Hadoop les nouvelles bibliothèques natives générées.
1
2
cd
sudo cp hadoop-2.3.0-src/hadoop-dist/target/hadoop-2.3.0/lib/native/* /usr/local/hadoop/lib/native
Pour vérifier que ce problème de bibliothèque native est résolu depuis Hadoop, démarrer le serveur de fichiers HDFS d’Hadoop et assurez-vous que l’avertissement a disparu, voir résultat ci-dessous :
1
2
3
4
5
6
$ start-dfs.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop-2.3.0/logs/hadoop-hduser-namenode-precise64.out
localhost: starting datanode, logging to /usr/local/hadoop-2.3.0/logs/hadoop-hduser-datanode-precise64.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.3.0/logs/hadoop-hduser-secondarynamenode-precise64.out
Références
Vous trouverez dans cette section, des liens qui m’ont été utiles pour la rédaction de cet article.
Installation
- Installation Hadoop V1 depuis la distribution Apache : http://www.michael-noll.com/tutorials/.
- Installation Hadoop V1 depuis la distribution Apache : http://cs.smith.edu/dftwiki/index.php/Hadoop_Tutorial_1–_Running_Wordcount%28rev_2%29.
- Différentes vidéos sur l’installation d’Hadoop V1 : http://www.hadoopscreencasts.com/.
- Installation Hadoop V1 en Français : http://blog.xebia.fr/2013/06/28/votre-premiere-installation-hadoop/.
- Installation Hadoop V1 sous Windows et développement du job MapReduce avec Eclipse : http://v-lad.org/Tutorials/Hadoop/00%20-%20Intro.html.
- Un tutoriel de Yahoo sur l’installation Hadoop V1 : https://developer.yahoo.com/hadoop/tutorial/index.html.
- Un tutoriel d’IBM sur l’installation Hadoop V1 : http://www.ibm.com/developerworks/data/library/techarticle/dm-1209hadoopbigdata/.
- Un tutoriel sur l’installation Hadoop V1 via la distribution Cloudera : http://4nil.quora.com/Cloudera-Hadoop-Installation-Ubuntu-Precise.
- Compiler les bibliothèques natives pour Apache Hadoop : http://www.ercoppa.org/Linux-Compile-Hadoop-220-fix-Unable-to-load-native-hadoop-library.htm.
- Installer Hadoop V2 sous Windows : http://www.srccodes.com/p/article/38/build-install-configure-run-apache-hadoop-2.2.0-microsoft-windows-os.
- Installer Hadoop V2 sous Linux : http://www.ercoppa.org/Linux-Install-Hadoop-220-on-Ubuntu-Linux-1304-Single-Node-Cluster.htm.
- Un autre tutoriel pour installer Hadoop V2 sous Linux : http://codesfusion.blogspot.fr/2013/10/setup-hadoop-2x-220-on-ubuntu.html.
Cours, Articles
- Un billet qui explique comment choisir sa distribution : http://www.infoq.com/fr/articles/BigDataPlatform.
- Documentation sur la version stable Apache Hadoop : http://hadoop.apache.org/docs/stable/index.html.
- Un billet qui montre comment dimensionner son cluster Hadoop : http://blog.octo.com/hadoop-dans-ma-dsi-comment-dimensionner-un-cluster/.
- Un billet sur WebHDFS : http://bighadoop.wordpress.com/2013/06/02/hadoop-rest-api-webhdfs.
Administration et outils
- Hue : http://cloudera.github.io/hue/.
- Ganglia : http://ganglia.sourceforge.net/.
- HiBench : https://github.com/intel-hadoop/HiBench et http://blog.octo.com/hadoop-dans-ma-dsi-benchmarker-son-cluster/.
Livres
- Hadoop Illuminated : http://hadoopilluminated.com/.
- Hadoop In Pratice : http://www.manning.com/holmes/.
- Hadoop Operations : http://shop.oreilly.com/product/0636920025085.do.
- Hadoop The Definitive Guide : http://shop.oreilly.com/product/0636920021773.do.
- Hadoop In Action : http://www.manning.com/lam/.
Je suis Mickaël BARON Ingénieur de Recherche en Informatique à l'ISAE-ENSMA et membre du laboratoire LIAS le jour
Veilleur Technologique la nuit
#Java #Container #VueJS #Services #WebSemantic

Derniers articles et billets