J'ai besoin ... d'une introduction à Hibernate OGM
- Prérequis logiciels
- Récupération des sources
- Construction des binaires Hibernate OGM
- Création d’un projet Maven avec une dépendance vers Hibernate OGM
- Création des classes entités
- Création du fichier de persistance (persistence.xml)
- Classe principale OrderRunner
- Conclusion
Pour rappel dans un précédent billet, lors de la dernière session du JUG Poitou-Charentes j’ai assisté à une présentation d’Hibernate OGM par Emmanuel BERNARD. Ce framework apporte la dimension ORM pour les solutions de stockage à base de clé/valeur. Plus précisément Hibernate OGM offre une implémentation JPA (manipulation d’objet et requêtes JP-QL) tout en stockant et requétant les données d’une grille clé/valeur. Ainsi, il offre une API familière tout en permettant de bénéficier des possibilités de scalabilité des solutions NoSQL. Hibernate OGM inclus notamment de supporter des applications JPA existantes.
Pour l’instant Hibernate OGM est en phase de prototype (version alpha). Il est actuellement possible de faire du CRUD avec des entités via l’API de JPA. Toutefois, les requêtes JP-QL ne sont pas encore prises en compte et seule la solution NoSQL Infinispan (clé/valeur) est supportée. Des dialects pour d’autres solutions clé/valeur et familles (orientées document et colonnes) sont à l’étude.
L’objectif de ce billet est dans un premier temps de montrer comment télécharger les sources d’Hibernate OGM à partir de eGIT, de construire ces sources afin d’obtenir le JAR et de l’exploiter dans un projet Maven (je me dis que ça pourra toujours servir). Dans un second temps, nous allons persister des entités à partir d’un modèle simple (commande de produits) et expliquer comment les données ont été stockées dans la solution de stockage Infinispan.
Prérequis logiciels
Cette section présente les logiciels utilisés pour la réalisation de ce billet.
- Eclipse 3.7 Indigo : la version actuelle lors de l’écriture de ce billet. Toutefois, un autre environnement pourrait bien sur faire l’affaire (IntelliJ ou Netbeans) ou même une version antérieure à Indigo.
- eGIT : le client GIT pour Eclipse ou tout autre client GIT avec ou sans intégration dans Eclipse.
- M2Eclipse : l’intégration Maven pour Eclipse. Ce plugin n’est pas obligatoire. Toutes les opérations d’exécution de commande Maven pouvant se faire à partir de l’invite de commande Windows.
- Maven 3 : l’outil de construction de binaire obligatoire pour construire le binaire d’Hibernate OGM. J’ai utilisé la version 3 mais la version 2 peut également faire l’affaire.
Dans la suite de ce billet, je suppose que tous ces outils sont déjà installés. Si vous avez des problèmes pour les installer, n’hésitez pas à vous rendre sur le site des outils où généralement un détail sur la procédure d’installation est disponible.
Récupération des sources
Cette section décrit toutes les étapes nécessaires à la récupération des sources d’Hibernate OGM et à la création d’un projet Java pour faciliter la construction du binaire d’Hibernate OGM.
-
Ouvrir la perspective GIT (Window -> Open Perspective -> Other … -> Git Respository Exploring).
-
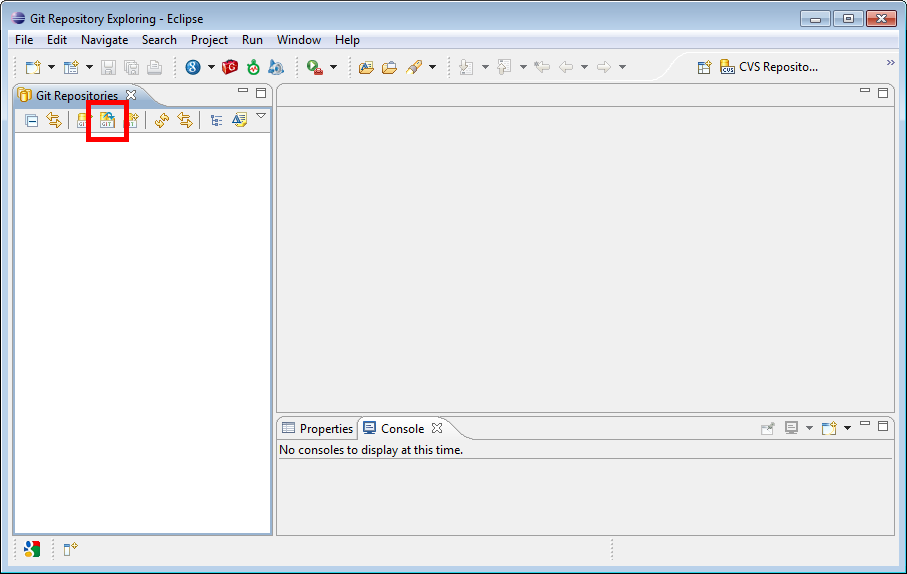
Cliquer sur l’action “Clone a GIT repository and add the clone to this view” (voir capture d’écran ci-dessous).
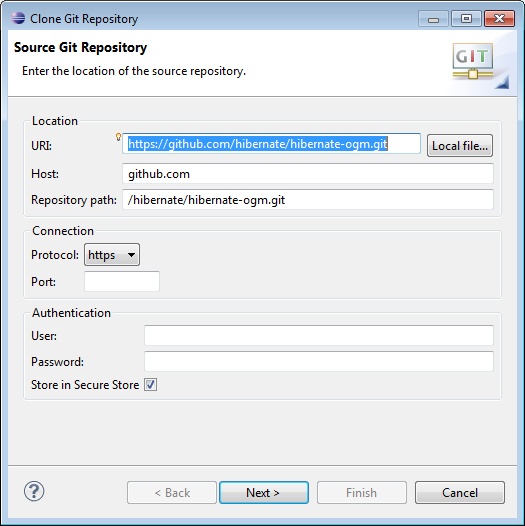
- Une boite de dialogue doit s’afficher et saisir les informations comme indiquées sur la capture d’écran ci-dessous puis faire Next (les sources d’Hibernate OGM se trouvent sur GITHub et l’URL est https://github.com/hibernate/hibernate-ogm.git).
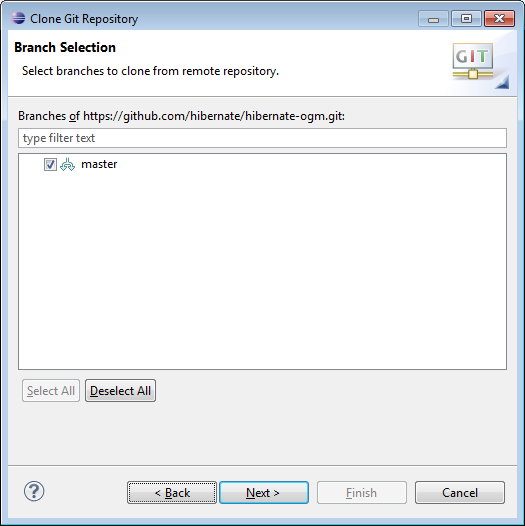
- Sélectionner Master puis faire Next (voir capture d’écran ci-dessous).
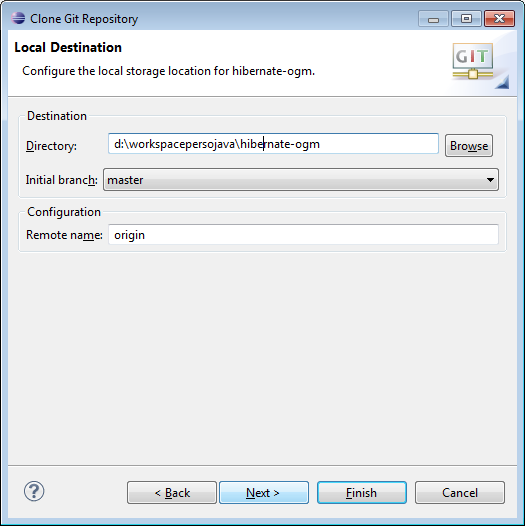
- Sélectionner le répertoire parent de votre Workspace et donner comme nom de répertoire cible le nom hibernate-ogm, puis faire Finish (voir capture d’écran ci-dessous). Les sources vont être téléchargés dans le répertoire précisé.
-
Pour transformer ce répertoire en un projet Java, ouvrir la perspective GIT Repository et déplier le nœud hibernate-ogm.
-
Afficher le menu contextuel à partir du sous nœud Working Directory et sélectionner l’élément Import Projects ….
-
Depuis la boite de dialogue qui vient de s’ouvrir, sélectionner le nœud Import as General Project et choisir le répertoire hibernate-ogm, puis faire Next (voir capture d’écran ci-dessous).
- Faire Finish pour que ce répertoire devienne un projet Java (voir capture d’écran ci-dessous).

-
Ouvrir la perspective Java.
-
Depuis le projet hibernate-ogm, afficher le menu contextuel et activer la gestion des dépendances Maven (Maven -> Enable Dependency Management).
Vous obtiendrez donc un projet appelé hibernate-ogm contenant à sa racine un fichier de description Maven parent. Deux sous modules sont disponibles hibernate-ogm-documentation et hibernate-ogm-core. Le projet hibernate-ogm-documentation contient une documentation présentant les grandes généralités d’Hibernate OGM. Ce projet contient également un exemple basique pour débuter. Le projet hibernate-ogm-core contient les sources et les tests unitaires du projet Hibernate OGM.
Construction des binaires Hibernate OGM
La construction des binaires se fait par l’intermédiaire de Maven et de la commande suivante à partir du premier fichier de description Maven.
1
mvn clean package
Possibilité de construire la documentation en utilisant la commande suivante
1
mvn clean install -DbuildDocs=true
Ou directement lancer la construction à partir du répertoire hibernate-ogm/hibernate-ogm-documentation
Création d’un projet Maven avec une dépendance vers Hibernate OGM
À partir d’Eclipse, créer un nouveau projet Maven et définir les paramètres d’identification du projet et de dépendances aux différentes bibliothèques comme cela est indiqué ci-après.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>keulkeul.hibernate.ogm</groupId>
<artifactId>keulkeul.hibernate.ogm.firstexample</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.hibernate.ogm</groupId>
<artifactId>hibernate-ogm-core</artifactId>
<version>3.0.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.12.1.GA</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.6.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.jboss.jbossts</groupId>
<artifactId>jbossjta</artifactId>
<version>4.15.0.Final</version>
<exclusions>...</exclusions>
</dependency>
</dependencies>
<pluginRepositories>
<pluginRepository>
<id>jboss-public-repository-group</id>
<name>JBoss Public Maven Repository Group</name>
<url>https://repository.jboss.org/nexus/content/groups/public-jboss/</url>
<layout>default</layout>
<releases>
<enabled>true</enabled>
<updatePolicy>never</updatePolicy>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
</pluginRepository>
</pluginRepositories>
<repositories>
<repository>
<id>jboss-public-repository-group</id>
<name>JBoss Public Maven Repository Group</name>
<url>https://repository.jboss.org/nexus/content/groups/public-jboss/</url>
<layout>default</layout>
<releases>
<enabled>true</enabled>
<updatePolicy>never</updatePolicy>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
</repository>
</repositories>
</project>
À noter que pour les exclusions de dépendances, ceci est rendu nécessaire dû fait de conflits entre versions de bibliothèques. La version complète du pom.xml est disponible dans les sources du projet fournis à la fin de ce billet.
Création des classes entités
Pour la suite, nous allons exploiter un exemple de gestion de commande. Puisque nous utilisons la convention de nommage anglophone pour le codage, le nom des classes et attributs seront écrites en anglais.
Une commande (Order) concerne un ensemble de produit (classe Product). Une commande contient une adresse de livraison (Address). Un produit fait partie d’une catégorie (Category). Ci-dessous sont présentées les classes, en détaillant les annotations JPA. Pour l’instant, rien de nouveau. Pour les développeurs ayant déjà des connaissances JPA ils retrouveront leurs marques. Par ailleurs, cet exemple tente de montrer l’implémentation de toutes les relations possibles.
À noter que toutes les classes définissent une clé primaire (que nous appellerons par la suite PK pour Primary Key). La déclaration de cette clé primaire est définie en JPA de cette manière.
1
2
3
4
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "RID", nullable = false)
private Long id;
Classe Address
Une adresse possède un seul attribut description de type chaine de caractères.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
@Entity
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "RID", nullable = false)
private Long id;
private String description;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
Classe Product
Un produit possède également une description et fait référence à une catégorie. Il y a une relation inverse qui permet d’obtenir l’ensemble des produits à partir d’une catégorie (voir ci-après).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
@Entity
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "RID", nullable = false)
private Long id;
@ManyToOne
@JoinColumn(name = "category\_fk")
private Category category;
private String description;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public Category getCategory() {
return category;
}
public void setCategory(Category category) {
this.category = category;
this.category.getProducts().add(this);
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
Classe Categoy
Une catégorie possède également une description. L’attribut products permet de représenter la relation inverse précédemment citée.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
@Entity
public class Category {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "RID", nullable = false)
private Long id;
@OneToMany(mappedBy = "category")
private List products;
private String description;
public Category() {
products = new ArrayList();
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public List getProducts() {
return products;
}
public void setProducts(List products) {
this.products = products;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
Classe Order
Une commande définit une liste de produits et une adresse.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
@Entity
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "RID", nullable = false)
private Long id;
@OneToOne
@JoinColumn(name = "address\_fk", nullable = false)
private Address deliveryAddress;
@OneToMany
@JoinTable(name = "t\_order\_product", joinColumns = {@JoinColumn(name="order\_fk")}, inverseJoinColumns = {@JoinColumn(name = "products\_fk")})
private List products;
public Address getDeliveryAddress() {
return deliveryAddress;
}
public void setDeliveryAddress(Address deliveryAddress) {
this.deliveryAddress = deliveryAddress;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public List getProducts() {
return products;
}
public void setProducts(List products) {
this.products = products;
}
}
Création du fichier de persistance (persistence.xml)
Vous trouverez ci-dessous le source du fichier persistence.xml utilisé pour préciser le provider et le type de transaction (ici via JTA).
1
2
3
4
5
6
7
8
9
<?xml version="1.0"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence\_2\_0.xsd" version="2.0">
<persistence-unit name="org.hibernate.ogm.tutorial.jpa" transaction-type="JTA">
<provider>org.hibernate.ogm.jpa.HibernateOgmPersistence</provider>
<properties>
<property name="hibernate.transaction.manager\_lookup\_class" value="org.hibernate.transaction.JBossTSStandaloneTransactionManagerLookup"/>
</properties>
</persistence-unit>
</persistence>
Classe principale OrderRunner
Nous détaillons dans la classe OrderRunner le programme servant 1) à persister les données 2) à extraire ces données et 3) à voir comment ces données sont stockées dans Infnispan. Dans les deux premiers problèmes, il n’y aura rien de nouveau. Nous utiliserons les mécanismes initiaux de JPA.
Persistances des données
Tout d’abord nous initialisons l’objet TransactionManager et l’EntityManagerFactory par rapport au contenu donné dans le fichier persistence.xml.
Par la suite nous ouvrons une transaction et nous initialisons des instances de notre modèle puis nous commitons. La fermeture de la transaction a pour effet de persister les données dans Infinispan. C’est donc Hibernate OGM qui se charge de passer de ce monde objet à un monde binaire (Map d’Infinispan).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
public class OrderRunner {
public static void main(String\[\] args) throws NotSupportedException, ... {
TransactionManager tm = new JBossTSStandaloneTransactionManagerLookup().getTransactionManager(null);
EntityManagerFactory emf = Persistence.createEntityManagerFactory("org.hibernate.ogm.tutorial.jpa");
tm.begin();
EntityManager em = emf.createEntityManager();
Address compagny = new Address();
compagny.setDescription("This is Address");
em.persist(compagny);
Category category = new Category();
category.setDescription("Multimedia");
em.persist(category);
Product product1 = new Product();
product1.setDescription("TV");
product1.setCategory(category);
em.persist(product1);
Product product2 = new Product();
product2.setDescription("Moto");
product2.setCategory(category);
em.persist(product2);
Order myOrder = new Order();
myOrder.setDeliveryAddress(compagny);
List products = new ArrayList();
products.add(product1);
products.add(product2);
myOrder.setProducts(products);
em.persist(myOrder);
em.flush();
em.close();
tm.commit();
...
Extraction des données
Par rapport aux précédentes instances, nous nous appuyons sur les identifiants existants pour extraire les données de la BD. Hibernate OGM effectue l’opération inverse et transforme une relation binaire en une représentation objet.
1
2
3
4
5
6
7
8
9
10
11
12
tm.begin();
em = emf.createEntityManager();
product1 = em.find(Product.class, product1.getId());
System.out.println(product1.getId());
product2 = em.find(Product.class, product2.getId());
System.out.println(product2.getId());
myOrder = em.find(Order.class, myOrder.getId());
System.out.println(myOrder.getId());
compagny = em.find(Address.class, compagny.getId());
System.out.println(compagny.getId());
category = em.find(Category.class, category.getId());
System.out.println(category.getId());
Données dans Infinispan
Nous faisons une extraction du cache d’Infinispan selon la session en cours. Puis nous réalisons un affichage du contenu de la Map.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
Cache entityCache = getEntityCache(em.unwrap(Session.class));
Set keySet = entityCache.keySet();
for (Object object : keySet) {
System.out.println(displayValue(entityCache, object));
}
em.flush();
em.close();
tm.rollback();
emf.close();
}
public static Cache getEntityCache(Session session) {
final SessionFactoryObserver observer = getObserver(session.getSessionFactory());
return ((GridMetadataManager) observer).getCacheContainer().getCache(GridMetadataManagerHelper.ENTITY\_CACHE);
}
private static SessionFactoryObserver getObserver(SessionFactory factory) {
final SessionFactoryObserver observer = ((SessionFactoryImplementor) factory).getFactoryObserver();
if (observer == null) {
throw new RuntimeException("Wrong OGM configuration: observer not set");
}
return observer;
}
private static String displayValue(Cache currentCache, Object key) {
String returnValue = key + " value";
Object value = currentCache.get(key);
if (value instanceof AtomicHashMap) {
AtomicHashMap infinispanCache = (AtomicHashMap) value;
returnValue += "{";
Set keySet = infinispanCache.keySet();
for (Object object : keySet) {
returnValue += object + "=" + infinispanCache.get(object) + ",";
}
returnValue = returnValue.substring(0, returnValue.length() - 1);
returnValue += "}";
} else {
returnValue += value;
}
return returnValue;
}
}
Nous obtenons le résultat ci-dessous.

Comme vous pouvez le constater les valeurs contiennent la sérialisation de l’instance d’une classe. Hibernate OGM se charge d’effectuer cette transformation à la fois pour la sérialisation et la désérialisation.
Conclusion
Cette première introduction montre les possibilités offerte par Hibernate OGM pour utiliser JPA dans le monde des solutions de stockage à la mode NoSQL. Le projet est très promoteur et reste à voir comment les requêtes JPQL pourront être intégrées dans les prochaines versions.
Toutefois même si Hibernate OGM permet à un développeur habitué à JPA de pouvoir exploiter la puissance de celui-ci pour les solutions types clé/valeur je n’arrive pas voir comment généraliser cela à tous les modèles à objets. En effet à la base un modèle à objet est fortement structuré (les valeurs nuls peuvent exprimer quelque chose) tandis que les solutions clé/valeur sont plus adaptées à des données faiblement structurées. Par ailleurs, il est dit que les solutions clé/valeur explose les temps pour la lecture. Qu’en est-il si mon besoin initial nécessite une forte sollicitation en écriture (update par exemple). Enfin, il pourrait être intéressant d’effectuer des tests de performance avec ou sans Hibernate OGM et de voir les apports en fonction des besoins initiaux (lecture, insert, update…).
Les sources de ce billet sont disponibles à cette adresse.
Je suis Mickaël BARON Ingénieur de Recherche en Informatique à l'ISAE-ENSMA et membre du laboratoire LIAS le jour
Veilleur Technologique la nuit
#Java #Container #VueJS #Services #WebSemantic

Derniers articles et billets